
Social media platforms are increasingly used to communicate crisis information when major disasters strike. Hence the rise of Big (Crisis) Data. Humanitarian organizations, digital humanitarians and disaster-affected communities know that some of this user-generated content can increase situational awareness. The challenge is to identify relevant and actionable content in near real-time to triangulate with other sources and make more informed decisions on the spot. Finding potentially life-saving information in this growing stack of Big Crisis Data, however, is like looking for the proverbial needle in a giant haystack. This is why my team and I at QCRI are developing AIDR.

The free and open source Artificial Intelligence for Disaster Response platform leverages machine learning to automatically identify informative content on Twitter during disasters. Unlike the vast majority of related platforms out there, we go beyond simple keyword search to filter for informative content. Why? Because recent research shows that keyword searches can miss over 50% of relevant content posted on Twitter. This is very far from optimal for emergency response. Furthermore, tweets captured via keyword search may not be relevant since words can have multiple meanings depending on context. Finally, keywords are restricted to one language only. Machine learning overcomes all these limitations, which is why we’re developing AIDR.
So how does AIDR work? There are three components of AIDR: the Collector, Trainer and Tagger. The Collector simply allows you to collect and save a collection of tweets posted during a disaster. You can download these tweets for analysis at any time and also use them to create an automated filter using machine learning, which is where the Trainer and Tagger come in. The Trainer allows one or more users to train the AIDR platform to automatically tag tweets of interest in a given collection of tweets. Tweets of interest could include those that refer to “Needs”, “Infrastructure Damage” or “Rumors” for example.
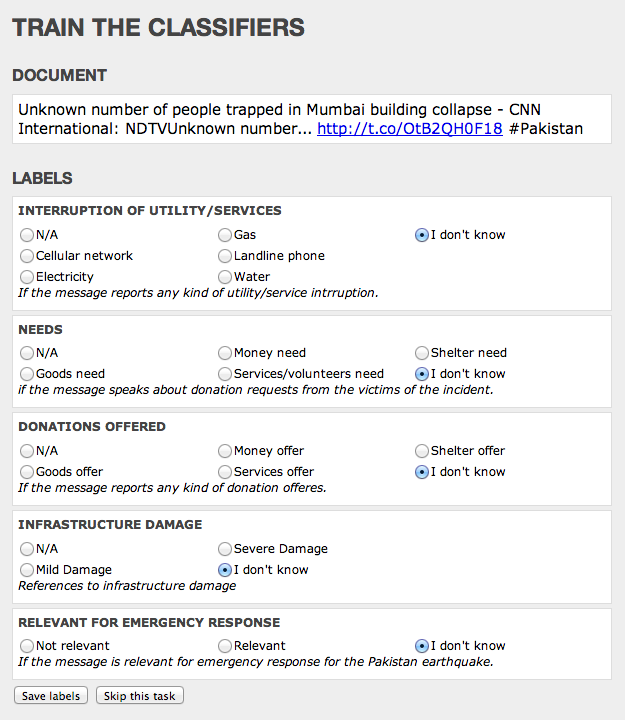
A user creates a Trainer for tweets-of-interest by: 1) Creating a name for their Trainer, e.g., “My Trainer”; 2) Identifying topics of interest such as “Needs”, “Infrastructure Damage”, “Rumors” etc. (as many topics as the user wants); and 3) Classifying tweets by topic of interest. This last step simply involves reading collected tweets and classifying them as “Needs”, “Infrastructure Damage”, “Rumor” or “Other,” for example. Any number of users can participate in classifying these tweets. That is, once a user creates a Trainer, she can classify the tweets herself, or invite her organization to help her classify, or ask the crowd to help classify the tweets, or all of the above. She simply shares a link to her training page with whoever she likes. If she choses to crowdsource the classification of tweets, AIDR includes a built-in quality control mechanism to ensure that the crowdsourced classification is accurate.
As noted here, we tested AIDR in response to the Pakistan Earthquake last week. We quickly hacked together the user interface displayed below, so functionality rather than design was our immediate priority. In any event, digital humanitarian volunteers from the Standby Volunteer Task Force (SBTF) tagged over 1,000 tweets based on the different topics (labels) listed below. As far as we know, this was the first time that a machine learning classifier was crowdsourced in the context of a humanitarian disaster. Click here for more on this early test.
The Tagger component of AIDR analyzes the human-classified tweets from the Trainer to automatically tag new tweets coming in from the Collector. This is where the machine learning kicks in. The Tagger uses the classified tweets to learn what kinds of tweets the user is interested in. When enough tweets have been classified (20 minimum), the Tagger automatically begins to tag new tweets by topic of interest. How many classified tweets is “enough”? This will vary but the more tweets a user classifies, the more accurate the Tagger will be. Note that each automatically tagged tweet includes an accuracy score—i.e., the probability that the tweet was correctly tagged by the automatic Tagger.
The Tagger thus displays a list of automatically tagged tweets updated in real-time. The user can filter this list by topic and/or accuracy score—display all tweets tagged as “Needs” with an accuracy of 90% or more, for example. She can also download the tagged tweets for further analysis. In addition, she can share the data link of her Tagger with developers so the latter can import the tagged tweets directly into to their own platforms, e.g., MicroMappers, Ushahidi, CrisisTracker, etc. (Note that AIDR already powers CrisisTracker by automating the classification of tweets). In addition, the user can share a display link with individuals who wish to embed the live feed into their websites, blogs, etc.
In sum, AIDR is an artificial intelligence engine developed to power consumer applications like MicroMappers. Any number of other tools can also be added to the AIDR platform, like the Credibility Plugin for Twitter that we’re collaborating on with partners in India. Added to AIDR, this plugin will score individual tweets based on the probability that they convey credible information. To this end, we hope AIDR will become a key node in the nascent ecosystem of next-generation humanitarian technologies. We plan to launch a beta version of AIDR at the 2013 CrisisMappers Conference (ICCM 2013) in Nairobi, Kenya this November.
In the meantime, we welcome any feedback you may have on the above. And if you want to help as an alpha tester, please get in touch so I can point you to the Collector tool, which you can start using right away. The other AIDR tools will be open to the same group of alpha tester in the coming weeks. For more on AIDR, see also this article in Wired.
![]()
The AIDR project is a joint collaboration with the United Nations Office for the Coordination of Humanitarian Affairs (OCHA). Other organizations that have expressed an interest in AIDR include the International Committee of the Red Cross (ICRC), American Red Cross (ARC), Federal Emergency Management Agency (FEMA), New York City’s Office for Emergency Management and their counterpart in the City of San Francisco.

Note: In the future, AIDR could also be adapted to take in Facebook status updates and text messages (SMS).

Pingback: Automatically Extracting Disaster-Relevant Information from Social Media | iRevolution
An ambitious and fascinating project.
What happens when Tweets have no hashtags? In other words, can this platform handle the real-time volume of information being added to the Twitterverse, or is it limited to subsets?
It seems pretty likely that most people using Twitter would want to include hashtags, my curiosity related to potential patterns with people who were just posting information for their friends/followers… Have you encountered any examples of that?
Thanks for reading, Sam, and for writing in.
The Collector allows users to search by keywords which don’t have to be hashtags. Without keywords of sorts, training a classifier for infrastructure damage in Pakistan, say, would be near impossible. There are some 400+million tweets posted every day. Humans would be hard-pressed to sift through 400+million tweets to find those that relate to Pakistan + infrastructure damage without an initial keyword search approach.
In terms of examples, we’re sifting through 740,000 tweets from the Westgate attach to see if we see any early tweets related to the event that don’t use any hashtags.
Thanks for the detail, Patrick! Looking forward to keeping my eye on this going forward. This is a terrific project.
Great article and extremely interesting project.
I am new to the world of crisis mapping and am trying to navigate the myriad of tools, papers and projects.
I have also been looking at SwiftRiver and I am wondering how AIDR relates/differs from SwiftRiver?
Many thanks,
Conor
Pingback: Humanitarian Crisis Computing 101 | iRevolution
Pingback: World Disaster Report: Next Generation Humanitarian Technology | iRevolution
Pingback: Digital Humanitarians: From Haiti Earthquake to Typhoon Yolanda | iRevolution
Pingback: Typhoon Yolanda – Update #1 | The Standby Task Force
Pingback: Re-thinking conflict early warning: big data and systems thinking | Let them talk
Pingback: Launching SBTF 2.0 : The RoadMap | The Standby Task Force
Pingback: Re-thinking conflict early warning: rapid context data in Syria and Libya | Let them talk
Pingback: The Best of iRevolution in 2013 | iRevolution
Pingback: New Insights on How To Verify Social Media | iRevolution
Pingback: Analyzing Tweets on Malaysia Flight #MH370 | iRevolution
Pingback: Digital Earth Action | What is EDIT?
Pingback: 5 herramientas imprescindibles para la verificación de contenido generado por ciudadanos | Periodismo Ciudadano
Pingback: El 4º Poder en Red » 5 herramientas imprescindibles para la verificación de contenido generado por ciudadanos
Pingback: Activation for Typhoon Hagupit (Ruby) -Update | Standby Task Force
Pingback: Wanted: Doha-based Software Engineer (Freelance) | Text on Techs
It’s fascinating to read about all your work. It has been one of the main drivers behind choosing my thesis topic of Big Data use in disaster relief after the Nepal earthquake. AIDR came up here as well. Does this mean it has been integrated into other tools you helped develop such as Micromappers or perhaps even your mapping with UAViators?
Thanks for reading, and for your kind note, Alice. Yes, AIDR has been integrated with MicroMappers; and MicroMappers has been used in context of UAViators deployment.