
My colleague ChaTo at QCRI recently shared some interesting thoughts on the challenges of crisis informatics research vis-a-vis Twitter as a source of real-time data. The way he drew out the issue was clear, concise and informative. So I’ve replicated his diagram below.
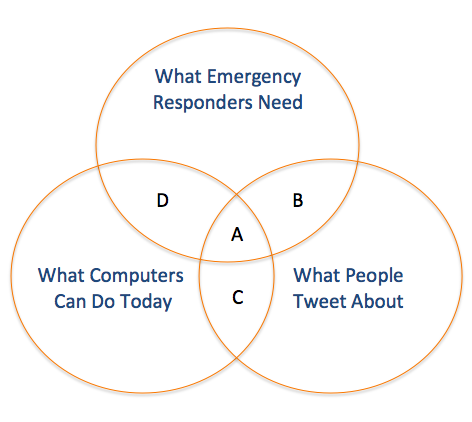
What Emergency Managers Need: Those actionable tweets that provide situational awareness relevant to decision-making. What People Tweet: Those tweets posted during a crisis which are freely available via Twitter’s API (which is a very small fraction of the Twitter Firehose). What Computers Can Do: The computational ability of today’s algorithms to parse and analyze natural language at a large scale.
A: The small fraction of tweets containing valuable information for emergency responders that computer systems are able to extract automatically.
B: Tweets that are relevant to disaster response but are not able to be analyzed in real-time by existing algorithms due to computational challenges (e.g. data processing is too intensive, or requires artificial intelligence systems that do not exist yet).
C: Tweets that can be analyzed by current computing systems, but do not meet the needs of emergency managers.
D: Tweets that, if they existed, could be analyzed by current computing systems, and would be very valuable for emergency responders—but people do not write such tweets.
These limitations are not just academic. They make it more challenging to develop next-generation humanitarian technologies. So one question that naturally arises is this: How can we expand the size of A? One way is for governments to implement policies that expand access to mobile phones and the Internet, for example.
Area C is where the vast majority of social media companies operate today, on collecting business intelligence and sentiment analysis for private sector companies by combining natural language processing and machine learning methodologies. But this analysis rarely focuses on tweets posted during a major humanitarian crisis. Reaching out to these companies to let them know they could make a difference during disasters would help to expand the size of A + C.
Finally, Area D is composed of information that would be very valuable for emergency responders, and that could automatically extracted from tweets, but that Twitter users are simply not posting this kind of information during emergencies (for now). Here, government and humanitarian organizations can develop policies to incentivise disaster-affected communities to tweet about the impact of a hazard and resulting needs in a way that is actionable, for example. This is what the Philippine Government did during Typhoon Pablo.
Now recall that the circle “What People Tweet About” is actually a very small fraction of all posted tweets. The advantage of this small sample of tweets is that they are freely available via Twitter’s API. But said API limits the number of downloadable tweets to just a few thousand per day. (For comparative purposes, there were over 20 million tweets posted during Hurricane Sandy). Hence the need for data philanthropy for humanitarian response.
I would be grateful for your feedback on these ideas and the conceptual frame-work proposed by ChaTo. The point to remember, as noted in this earlier post, is that today’s challenges are not static; they can be addressed and overcome to various degrees. In other words, the sizes of the circles can and will change.

One important difference between the current tweet stream and what ‘could be’, is the recognition that disaster messages are important enough to have a life of their own. Relying upon facebook and twitter will always be inadequate. Moving instead to a model where free messaging is provided during emergencies and supported by specific mechanisms to handle the traffic is the only truly scaleable means. Investment should be a no brainer for city governments because the value of spontaneous incoming messages is far greater than efforts to scour meaning from social media.