
The “field” of information forensics has seen some interesting developments in recent weeks. Take the Verification Handbook or Twitter Lie-Detector project, for example. The Social Sensor project is yet another new initiative. In this blog post, I seek to make sense of these new developments and to identify where this new field may be going. In so doing, I highlight key insights from each initiative.

The co-editors of the Verification Handbook remind us that misinformation and rumors are hardly new during disasters. Chapter 1 opens with the following account from 1934:
“After an 8.1 magnitude earthquake struck northern India, it wasn’t long before word circulated that 4,000 buildings had collapsed in one city, causing ‘innumerable deaths.’ Other reports said a college’s main building, and that of the region’s High Court, had also collapsed.”
These turned out to be false rumors. The BBC’s User Generated Content (UGC) Hub would have been able to debunk these rumors. In their opinion, “The business of verifying and debunking content from the public relies far more on journalistic hunches than snazzy technology.” So they would have been right at home in the technology landscape of 1934. To be sure, they contend that “one does not need to be an IT expert or have special equipment to ask and answer the fundamental questions used to judge whether a scene is staged or not.” In any event, the BBC does not “verify something unless [they] speak to the person that created it, in most cases.” What about the other cases? How many of those cases are there? And how did they ultimately decide on whether the information was true or false even though they did not speak to the person that created it?
As this new study argues, big news organizations like the BBC aim to contact the original authors of user generated content (UGC) not only to try and “protect their editorial integrity but also because rights and payments for newsworthy footage are increasingly factors. By 2013, the volume of material and speed with which they were able to verify it [UGC] were becoming significant frustrations and, in most cases, smaller news organizations simply don’t have the manpower to carry out these checks” (Schifferes et al., 2014).

Chapter 3 of the Handbook notes that the BBC’s UGC Hub began operations in early 2005. At the time, “they were reliant on people sending content to one central email address. At that point, Facebook had just over 5 million users, rather than the more than one billion today. YouTube and Twitter hadn’t launched.” Today, more than 100 hours of content is uploaded to YouTube every minute; over 400 million tweets are sent each day and over 1 million pieces of content are posted to Facebook every 30 seconds. Now, as this third chapter rightly notes, “No technology can automatically verify a piece of UGC with 100 percent certainty. However, the human eye or traditional investigations aren’t enough either. It’s the combination of the two.” New York Times journalists concur: “There is a problem with scale… We need algorithms to take more onus off human beings, to pick and understand the best elements” (cited in Schifferes et al., 2014).
People often (mistakenly) see “verification as a simple yes/no action: Something has been verified or not. In practice, […] verification is a process” (Chapter 3). More specifically, this process is one of satisficing. As colleagues Leysia Palen et al. note in this study, “Information processing during mass emergency can only satisfice because […] the ‘complexity of the environment is immensely greater than the computational powers of the adaptive system.'” To this end, “It is an illusion to believe that anyone has perfectly accurate information in mass emergency and disaster situations to account for the whole event. If someone did, then the situation would not be a disaster or crisis.” This explains why Leysia et al seek to shift the debate to one focused on the helpfulness of information rather the problematic true/false dichotomy.

“In highly contextualized situations where time is of the essence, people need support to consider the content across multiple sources of information. In the online arena, this means assessing the credibility and content of information distributed across [the web]” (Leysia et al., 2011). This means that, “Technical support can go a long way to help collate and inject metadata that make explicit many of the inferences that the every day analyst must make to assess credibility and therefore helpfulness” (Leysia et al., 2011). In sum, the human versus computer debate vis-a-vis the verification of social media is somewhat pointless. The challenge moving forward resides in identifying the best ways to combine human cognition with machine computing. As Leysia et al. rightly note, “It is not the job of the […] tools to make decisions but rather to allow their users to reach a decision as quickly and confidently as possible.”
This may explain why Chapter 7 (which I authored) applies both human and advanced computing techniques to the verification challenge. Indeed, I explicitly advocate for a hybrid approach. In contrast, the Twitter Lie-Detector project known as Pheme apparently seeks to use machine learning alone to automatically verify online rumors as they spread on social networks. Overall, this is great news—the more groups that focus on this verification challenge, the better for those us engaged in digital humanitarian response. It remains to be seen, however, whether machine learning alone will make Pheme a success.

In the meantime, the EU’s Social Sensor project is developing new software tools to help journalists assess the reliability of social media content (Schifferes et al., 2014). A preliminary series of interviews revealed that journalists were most interested in Social Sensor software for:
1. Predicting or alerting breaking news
2. Verifying social media content–quickly identifying who has posted a tweet or video and establishing “truth or lie”
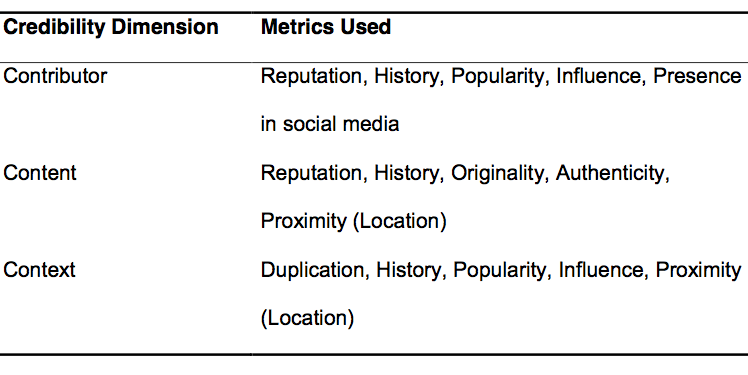
So the Social Sensor project is developing an “Alethiometer” (Alethia is Greek for ‘truth’) to “meter the credibility of of information coming from any source by examining the three Cs—Contributors, Content and Context. These seek to measure three key dimensions of credibility: the reliability of contributors, the nature of the content, and the context in which the information is presented. This reflects the range of considerations that working journalists take into account when trying to verify social media content. Each of these will be measured by multiple metrics based on our research into the steps that journalists go through manually. The results of [these] steps can be weighed and combined [metadata] to provide a sense of credibility to guide journalists” (Schifferes et al., 2014).
On our end, my colleagues and at QCRI are continuing to collaborate with several partners to experiment with advanced computing methods to address the social media verification challenge. As noted in Chapter 7, Verily, a platform that combines time-critical crowdsourcing and critical thinking, is still in the works. We’re also continuing our collaboration on a Twitter credibility plugin (more in Chapter 7). In addition, we are exploring whether we can microtask the computation of source credibility scores using MicroMappers.
Of course, the above will sound like “snazzy technologies” to seasoned journalists with no background or interest in advanced computing. But this doesn’t seem to stop them from complaining that “Twitter search is very hit and miss;” that what Twitter “produces is not comprehensive and the filters are not comprehensive enough” (BBC social media expert, cited in Schifferes et al., 2014). As one of my PhD dissertation advisors (Clay Shirky) noted a while back already, information overflow (Big Data) is due to “Filter Failure”. This is precisely why my colleagues and I are spending so much of our time developing better filters—filters powered by human and machine computing, such as AIDR. These types of filters can scale. BBC journalists on their own do not, unfortunately. But they can act on hunches and intuition based on years of hands-on professional experience.
The “field” of digital information forensics has come along way since I first wrote about how to verify social media content back in 2011. While I won’t touch on the Handbook’s many other chapters here, the entire report is an absolute must read for anyone interested and/or working in the verification space. At the very least, have a look at Chapter 9, which combines each chapter’s verification strategies in the form of a simple check-list. Also, Chapter 10 includes a list of tools to aid in the verification process.
In the meantime, I really hope that we end the pointless debate about human versus machine. This is not an either/or issue. As a colleague once noted, what we really need is a way to combine the power of algorithms and the wisdom of the crowd with the instincts of experts.

See also:
- Predicting the Credibility of Disaster Tweets Automatically [link]
- Auto-Ranking Credibility of Tweets During Major Events [link]
- Auto-Identifying Fake Images on Twitter During Disasters [link]
- Truth in the Age of Social Media: A Big Data Challenge [link]
- Analyzing Fake Content on Twitter During Boston Bombings [link]
- How to Verify Crowdsourced Information from Social Media [link]
- Crowdsourcing Critical Thinking to Verify Social Media [link]

Reblogged this on matharevalley and commented:
This is a must read for people in the field of social media.
Very interesting. I’m a co-proposer of Pheme and really glad you mentioned it in this article so it caught my attention; I’m looking forward to reading your research on the topic.
Thanks for reading, Leon. Looking forward to following your progress!
Very interesting and very convincing piece of work; we are definitly going to apply these guidelines for rapid earthquake impact assesment.
Pingback: The Steep Slope of the Data Revolution’s Second Derivative | Dart-Throwing Chimp
Pingback: Got TweetCred? Use it To Automatically Identify Credible Tweets | iRevolution