Humanitarian organizations need both timely and accurate information when responding to disasters. Where is the most damage located? Who needs the most help? What other threats exist? Respectable news organizations also need timely and accurate information during crisis events to responsibly inform the public. Alas, both humanitarian & mainstream news organizations are often confronted with countless rumors and unconfirmed reports. Investigative journalists and others have thus developed a number of clever strategies to rapidly verify such reports—as detailed in the excellent Verification Handbook. There’s just one glitch: Journalists and humanitarians alike are increasingly overwhelmed by the “Big Data” generated during crises, particularly information posted on social media. They rarely have enough time or enough staff to verify the majority of unconfirmed reports. This is where Verily comes in, a new type of Detective Agency for a new type of detective: The Virtual Digital Detective.

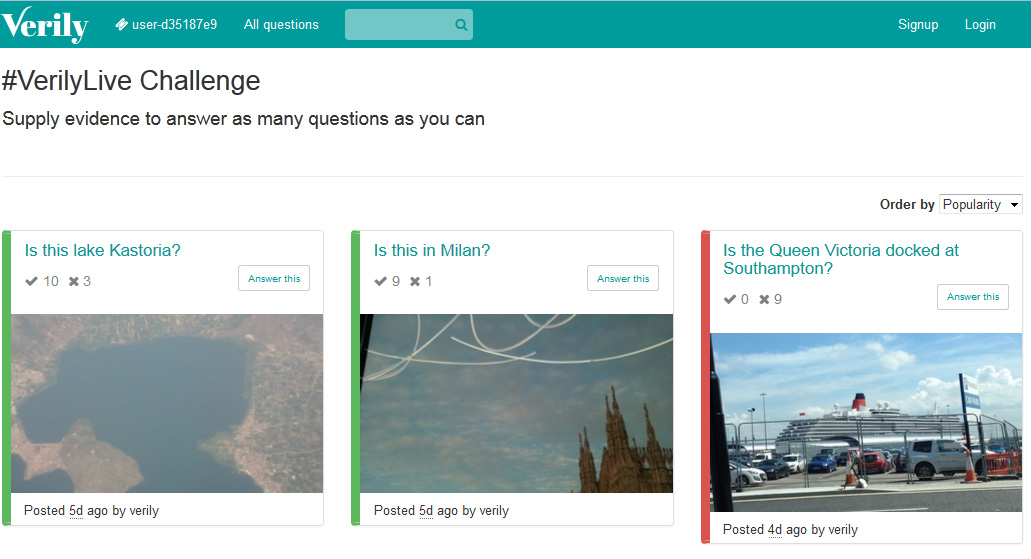
The purpose of Verily is to rapidly crowdsource the verification of unconfirmed reports during major disasters. The way it works is simple. If a humanitarian or news organization has a verification request, they simply submit this request online at Verily. This request must be phrased in the form of a Yes-or-No question, such as: “Has the Brooklyn Bridge been destroyed by the Hurricane?”; “Is this Instagram picture really showing current flooding in Indonesia”?; “Is this new YouTube video of the Chile earthquake fake?”; “Is it true that the bush fires in South Australia are getting worse?” and so on.
Verily helps humanitarian & news organizations find answers to these questions by rapidly crowdsourcing the collection of clues that can help answer said questions. Verification questions are communicated widely across the world via Verily’s own email-list of Digital Detectives and also via social media. This new bread of Digital Detectives then scour the web for clues that can help answer the verification questions. Anyone can become a Digital Detective at Verily. Indeed, Verily provides a menu of mini-verification guides for new detectives. These guides were written by some of the best Digital Detectives on the planet, the authors of the Verification Handbook. Verily Detectives post the clues they find directly to Verily and briefly explain why these clues help answer the verification question. That’s all there is to it.

If you’re familiar with Reddit, you may be thinking “Hold on, doesn’t Reddit do this already?” In part yes, but Reddit is not necessarily designed to crowdsource critical thinking or to create skilled Digital Detectives. Recall this fiasco during the Boston Marathon Bombings which fueled disastrous “witch hunts”. Said disaster would not have happened on Verily because Verily is deliberately designed to focus on the process of careful detective work while providing new detectives with the skills they need to precisely avoid the kind of disaster that happened on Reddit. This is no way a criticism of Reddit! One single platform alone cannot be designed to solve every problem under the sun. Deliberate, intentional design is absolutely key.
In sum, our goal at Verily is to crowdsource Sherlock Holmes. Why do we think this will work? For several reasons. First, authors of the Verification Handbook have already demonstrated that individuals working alone can, and do, verify unconfirmed reports during crises. We believe that creating a community that can work together to verify rumors will be even more powerful given the Big Data challenge. Second, each one of us with a mobile phone is a human sensor, a potential digital witness. We believe that Verily can help crowdsource the search for eyewitnesses, or rather the search for digital content that these eyewitnesses post on the Web. Third, the Red Balloon Challenge was completed in a matter of hours. This Challenge focused on crowdsourcing the search for clues across an entire continent (3 million square miles). Disasters, in contrast, are far more narrow in terms of geographic coverage. In other words, the proverbial haystack is smaller and thus the needles easier to find. More on Verily here & here.
So there’s reason to be optimistic that Verily can succeed given the above and recent real-world deployments. Of course, Verily is is still very much in early phase and still experimental. But both humanitarian organizations and high-profile news organizations have expressed a strong interest in field-testing this new Digital Detective Agency. To find out more about Verily and to engage with experts in verification, please join us on Tuesday, March 3rd at 10:00am (New York time) for this Google Hangout with the Verily Team and our colleague Craig Silverman, the Co-Editor of the Verification Handbook. Click here for the Event Page and here to follow on YouTube. You can also join the conversations on Twitter and pose questions or comments using the hashtag #VerilyLive.