As part of QCRI’s Artificial Intelligence for Monitoring Elections (AIME) project, I liaised with Kaggle to work with a top notch Data Scientist to carry out a proof of concept study. As I’ve blogged in the past, crowdsourced election monitoring projects are starting to generate “Big Data” which cannot be managed or analyzed manually in real-time. Using the crowdsourced election reporting data recently collected by Uchaguzi during Kenya’s elections, we therefore set out to assess whether one could use machine learning to automatically tag user-generated reports according to topic, such as election-violence. The purpose of this post is to share the preliminary results from this innovative study, which we believe is the first of it’s kind.

The aim of this initial proof-of-concept study was to create a model to classify short messages (crowdsourced election reports) into several predetermined categories. The classification models were developed by applying a machine learning technique called gradient boosting on word features extracted from the text of the election reports along with their titles. Unigrams, bigrams and the number of words in the text and title were considered in the model development. The tf-idf weighting function was used following internal validation of the model.
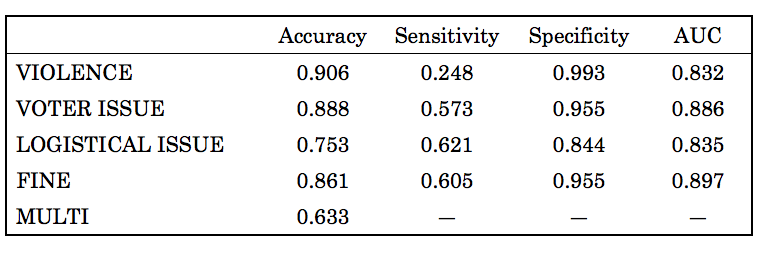
The results depicted above confirm that classifiers can be developed to automatically classify short election observation reports crowdsourced from the public. The classification was generated by 10-fold cross validation. Our classifier is able to correctly predict whether a report is related to violence with an accuracy of 91%, for example. We can also accurately predict 89% of reports that relate to “Voter Issues” such as registration issues and reports that indicate positive events, “Fine” (86%).
The plan for this Summer and Fall is to replicate this work for other crowdsourced election datasets from Ghana, Liberia, Nigeria and Uganda. We hope the insights gained from this additional research will reveal which classifiers and/or “super classifiers” are portable across certain countries and election types. Our hypothesis, based on related crisis computing research, is that classifiers for certain types of events will be highly portable. However, we also hypothesize that the application of most classifiers across countries will result in lower accuracy scores. To this end, our Artificial Intelligence for Monitoring Elections platform will allow election monitoring organizations (end users) to create their own classifiers on the fly and thus meet their own information needs.

Big thanks to Nao for his excellent work on this predictive modeling project.