There is so much attention (and hype) around the use of social media for emergency management (SMEM) that we often forget about mainstream media when it comes to next generation humanitarian technologies. The news media across the globe has become increasingly digital in recent years—and thus analyzable in real-time. Twitter added little value during the recent Pakistan Earthquake, for example. Instead, it was the Pakistani mainstream media that provided the immediate situational awareness necessary for a preliminary damage and needs assessment. This means that our humanitarian technologies need to ingest both social media and mainstream media feeds.

Now, this is hardly revolutionary. I used to work for a data mining company ten years ago that focused on analyzing Reuters Newswires in real-time using natural language processing (NLP). This was for a conflict early warning system we were developing. The added value of monitoring mainstream media for crisis mapping purposes has also been demonstrated repeatedly in recent years. In this study from 2008, I showed that a crisis map of Kenya was more complete when sources included mainstream media as well as user-generated content.
So why revisit mainstream media now? Simple: GDELT. The Global Data Event, Language and Tone dataset that my colleague Kalev Leetaru launched earlier this year. GDELT is the single largest public and global event-data catalog ever developed. Digital Humanitarians need no longer monitor mainstream media manually. We can simply develop a dedicated interface on top of GDELT to automatically extract situational awareness information for disaster response purposes. We’re already doing this with Twitter, so why not extend the approach to global digital mainstream media as well?
GDELT data is drawn from a “cross-section of all major international, national, regional, local, and hyper-local news sources, both print and broadcast, from nearly every corner of the globe, in both English and vernacular.” All identified events are automatically coded using the CAMEO coding framework (although Kalev has since added several dozen additional event-types). In short, GDELT codes all events by the actors involved, the type of event, location, time and other meta-data attributes. For example, actors include “Refugees,” “United Nations,” and “NGO”. Event-types include variables such as “Affect” which captures everything from refugees to displaced persons, evacuations, etc. Humanitarian crises, aid, disasters, disaster relief, etc. are also included as an event-type. The “Provision of Humanitarian Aid” is another event-type, for example. GDELT data is currently updated every 24 hours, and Kalev has plans to provide hourly updates in the near future and ultimately 30-minute updates.
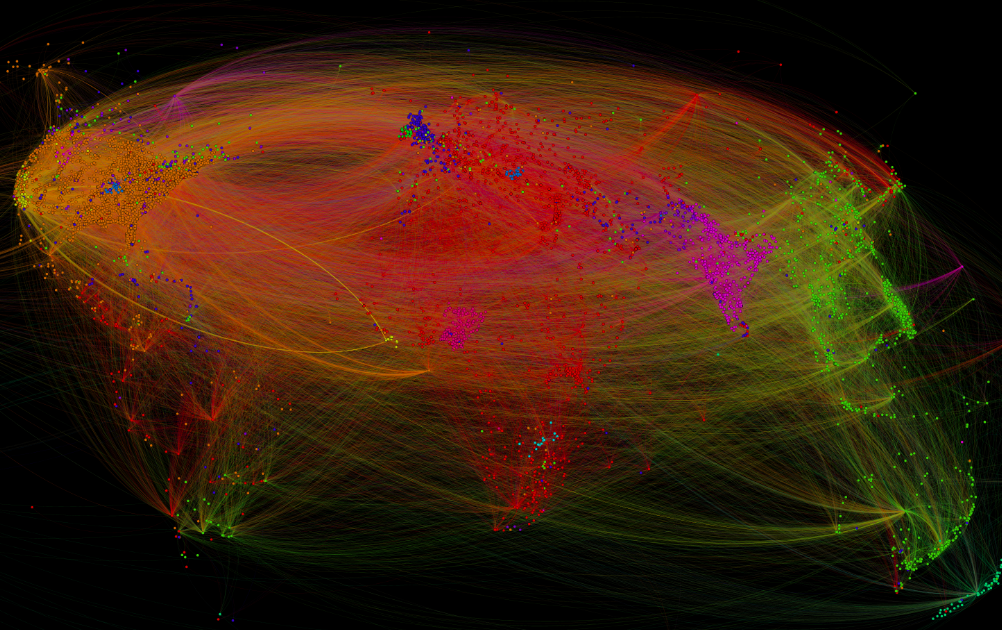
If this isn’t impressive enough, Kalev and colleagues have just launched the GDELT Global Knowledge Graph (GKG). “To sum up the GKG in a single sentence, it connects every person, organization, location, count, theme, news source, and event across the planet into a single massive network that captures what’s happening around the world, what its context is and who’s involved, and how the world is feeling about it, every single day.” The figure above (click to enlarge) is based on a subset of a single day of the GDELT Knowledge Graph, showing “how the cities of the world are connected to each other in a single day’s worth of news. A customized version of the GKG could perhaps prove useful for UN OCHA’s “Who Does What, Where” (3Ws) directory in the future.
I’ve had long conversations with Kalev this month about leveraging GDELT for disaster response and he is very supportive of the idea. My hope is that we’ll be able to add a GDELT feed to MicroMappers next year. I’m also wondering whether we could eventually create a version of the AIDR platform that ingests GDELT data instead (or in addition to) Twitter. There is real potential here, which is why I’m excited that my colleagues at OCHA are exploring GDELT for humanitarian response. I’ll be meeting with them this week and next to explore ways to collaborate on making the most of GDELT for humanitarian response.

Note: Mainstream media obviously includes television and radio as well. Some colleagues of mine in Austria are looking at triangulating television broadcasts with text-based media and social media for a European project.