I’m always amazed by folks who dismiss the value of social media for emergency management based on the perception that said content is useless for disaster response. In that case, libraries are also useless (bar the few books you’re looking for, but those rarely represent more than 1% of all the books available in a major library). Does that mean libraries are useless? Of course not. Is social media useless for disaster response? Of course not. Even if only 0.001% of the 20+ million tweets posted during Hurricane Sandy were useful, and only half of these were accurate, this would still mean over 1,000 real-time and informative tweets, or some 15,000 words—i.e., the equivalent of a 25-page, single-space document exclusively composed of fully relevant, actionable & timely disaster information.

Empirical studies clearly prove that social media reports can be informative for disaster response. Numerous case studies have also described how social media has saved lives during crises. That said, if emergency responders do not actively or explicitly create demand for relevant and high quality social media content during crises, then why should supply follow? If the 911 emergency number (999 in the UK) were never advertised, then would anyone call? If 911 were simply a voicemail inbox with no instructions, would callers know what type of actionable information to relay after the beep?
While the majority of emergency management centers do not create the demand for crowdsourced crisis information, members of the public are increasingly demanding that said responders monitor social media for “emergency posts”. But most responders fear that opening up social media as a crisis communication channel with the public will result in an unmanageable flood of requests, The London Fire Brigade seems to think otherwise, however. So lets carefully unpack the fear of information flooding.
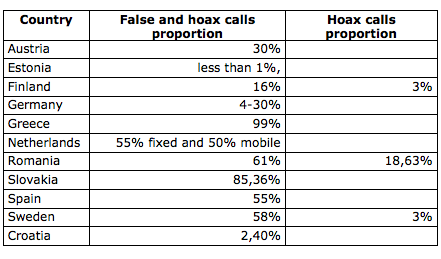
First of all, New York City’s 911 operators receive over 10 million calls every year that are accidental, false or hoaxes. Does this mean we should abolish the 911 system? Of course not. Now, assuming that 10% of these calls takes an operator 10 seconds to manage, this represents close to 3,000 hours or 115 days worth of “wasted work”. But this filtering is absolutely critical and requires human intervention. In contrast, “emergency posts” published on social media can be automatically filtered and triaged thanks to Big Data Analytics and Social Computing, which could save time operators time. The Digital Operations Center at the American Red Cross is currently exploring this automated filtering approach. Moreover, just as it is illegal to report false emergency information to 911, there’s no reason why the same laws could not apply to social media when these communication channels are used for emergency purposes.
Second, if individuals prefer to share disaster related information and/or needs via social media, this means they are less likely to call in as well. In other words, double reporting is unlikely to occur and could also be discouraged and/or penalized. In other words, the volume of emergency reports from “the crowd” need not increase substantially after all. Those who use the phone to report an emergency today may in the future opt for social media instead. The only significant change here is the ease of reporting for the person in need. Again, the question is one of supply and demand. Even if relevant emergency posts were to increase without a comparable fall in calls, this would simply reveal that the current voice-based system creates a barrier to reporting that discriminates against certain users in need.
Third, not all emergency calls/posts require immediate response by a paid professional with 10+ years of experience. In other words, the various types of needs can be triaged and responded to accordingly. As part of their police training or internships, new cadets could be tasked to respond to less serious needs, leaving the more seasoned professionals to focus on the more difficult situations. While this approach certainly has some limitations in the context of 911, these same limitations are far less pronounced for disaster response efforts in which most needs are met locally by the affected communities themselves anyway. In fact, the Filipino government actively promotes the use of social media reporting and crisis hashtags to crowdsource disaster response.
In sum, if disaster responders and emergency management processionals are not content with the quality of crisis reporting found on social media, then they should do something about it by implementing the appropriate policies to create the demand for higher quality and more structured reporting. The first emergency telephone service was launched in London some 80 years ago in response to a devastating fire. At the time, the idea of using a phone to report emergencies was controversial. Today, the London Fire Brigade is paving the way forward by introducing Twitter as a reporting channel. This move may seem controversial to some today, but give it a few years and people will look back and ask what took us so long to adopt new social media channels for crisis reporting.