
Wish you had a better way to make sense of Twitter during disasters than this?

Type in a keyword like #ChileEarthquake in Twitter’s search box above and you’ll see more tweets than you can possibly read in a day let alone keep up with for more than a few minutes. Wish there way were an easy, free and open source solution? Well you’ve come to the right place. My team and I at QCRI are developing the Artificial Intelligence for Disaster Response (AIDR) platform to do just this. Here’s how it works:
First you login to the AIDR platform using your own Twitter handle (click images below to enlarge):
You’ll then see your collection of tweets (if you already have any). In my case, you’ll see I have three. The first is a collection of English language tweets related to the Chile Earthquake. The second is a collection of Spanish tweets. The third is a collection of more than 3,000,000 tweets related to the missing Malaysia Airlines plane. A preliminary analysis of these tweets is available here.
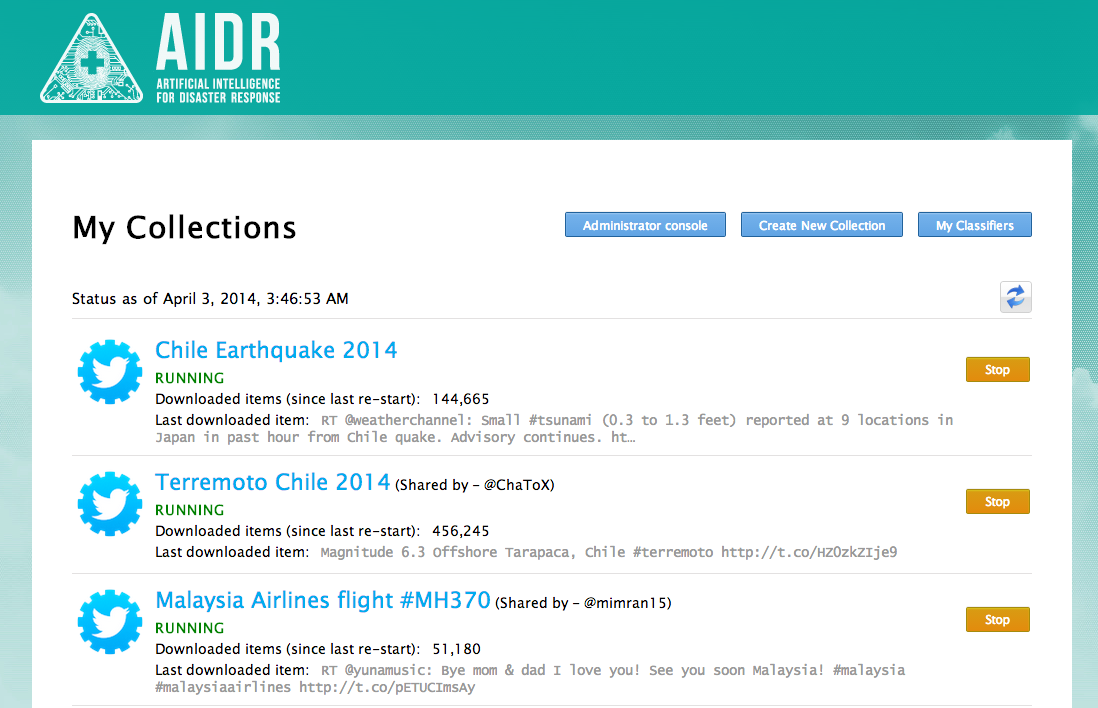
Lets look more closely at my Chile Earthquake 2014 collection (see below, click to enlarge). I’ve collected about a quarter of a million tweets in the past 30 hours or so. The label “Downloaded tweets (since last re-start)” simply refers to the number of tweets I’ve collected since adding a new keyword or hashtag to my collection. I started the collection yesterday at 5:39am my time (yes, I’m an early bird). Under “Keywords” you’ll see all the hashtags and keywords I’ve used to search for tweets related to the earthquake in Chile. I’ve also specified the geographic region I want to collect tweets from. Don’t worry, you don’t actually have to enter geographic coordinates when you set up your own collection, you simply highlight (on map) the area you’re interested in and AIDR does the rest.

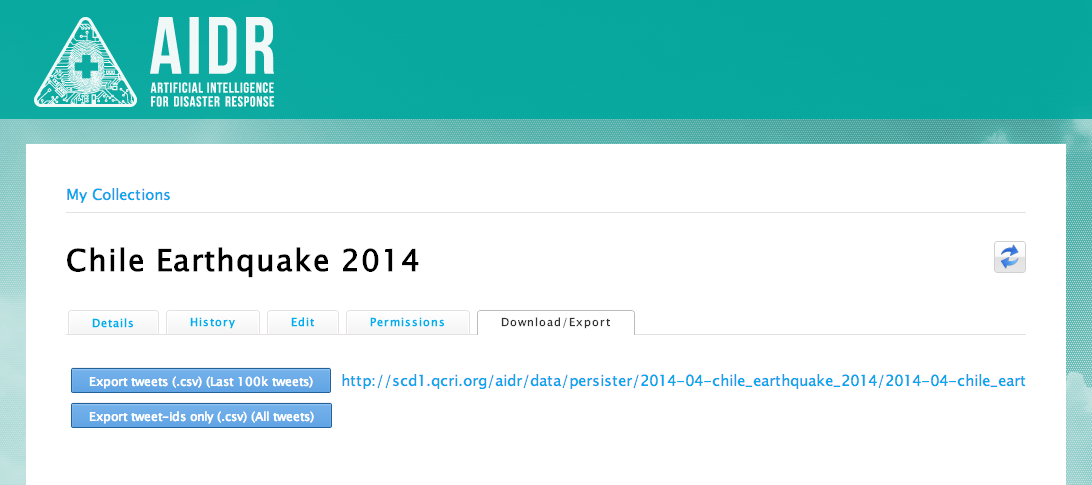
You’ll also note in the above screenshot that I’ve selected to only collect tweets in English, but you can collect all language tweets if you’d like or just a select few. Finally, the Collaborators section simply lists the colleagues I’ve added to my collection. This gives them the ability to add new keywords/hashtags and to download the tweets collected as shown below (click to enlarge). More specifically, collaborators can download the most recent 100,000 tweets (and also share the link with others). The 100K tweet limit is based on Twitter’s Terms of Service (ToS). If collaborators want all the tweets, Twitter’s ToS allows for sharing the TweetIDs for an unlimited number of tweets.
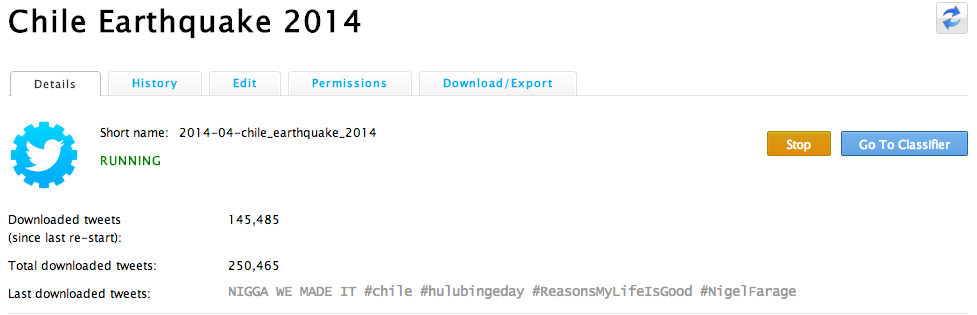
So that’s the AIDR Collector. We also have the AIDR Classifier, which helps you make sense of the tweets you’re collecting (in real-time). That is, your collection of tweets doesn’t stop, it continues growing, and as it does, you can make sense of new tweets as they come in. With the Classifier, you simply teach AIDR to classify tweets into whatever topics you’re interested in, like “Infrastructure Damage”, for example. To get started with the AIDR Classifier, simply return to the “Details” tab of our Chile collection. You’ll note the “Go To Classifier” button on the far right:
Clicking on that button allows you to create a Classifier, say on the topic of disaster damage in general. So you simply create a name for your Classifier, in this case “Disaster Damage” and then create Tags to capture more details with respect to damage-related tweets. For example, one Tag might be, say, “Damage to Transportation Infrastructure.” Another could be “Building Damage.” In any event, once you’ve created your Classifier and corresponding tags, you click Submit and find your way to this page (click to enlarge):
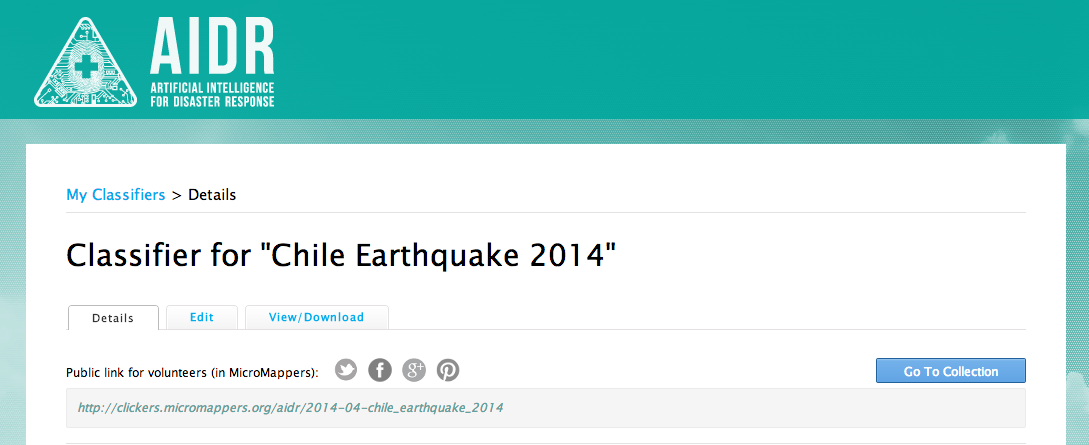
You’ll notice the public link for volunteers. That’s basically the interface you’ll use to teach AIDR. If you want to teach AIDR by yourself, you can certainly do so. You also have the option of “crowdsourcing the teaching” of AIDR. Clicking on the link will take you to the page below.
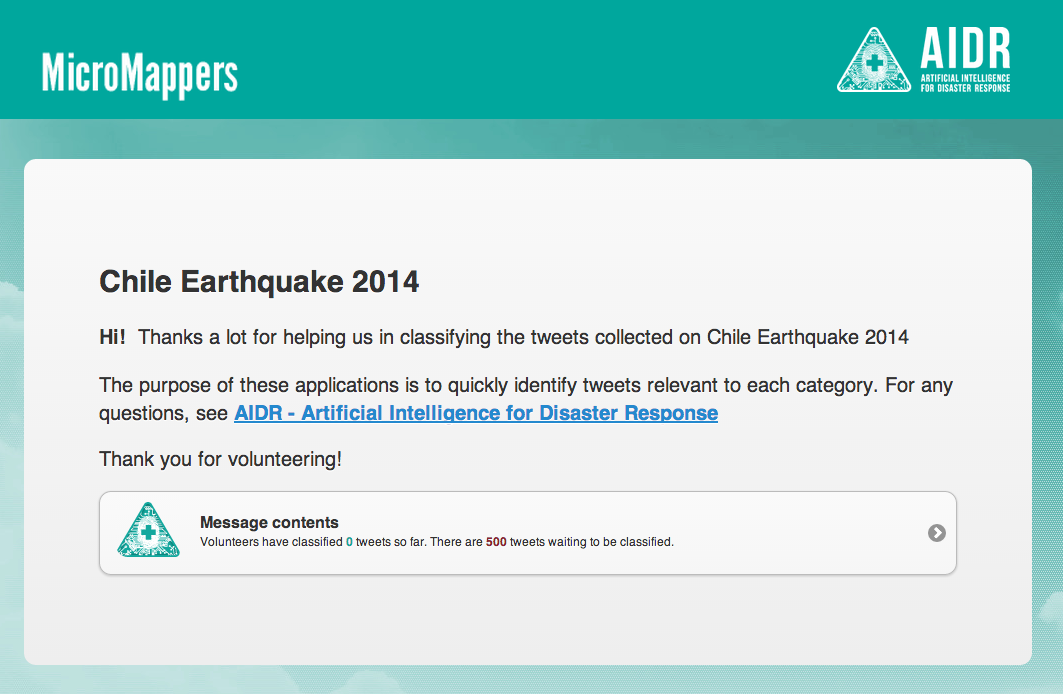
So, I called my Classifier “Message Contents” which is not particularly insightful; I should have labeled it something like “Humanitarian Information Needs” or something, but bear with me and lets click on that Classifier. This will take you to the following Clicker on MicroMappers:
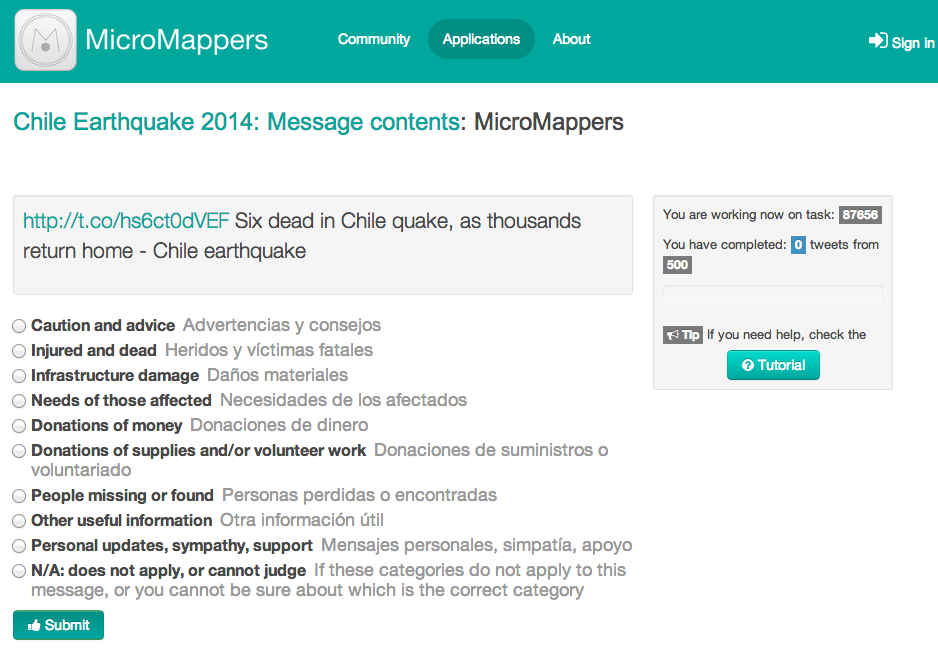
Now this is not the most awe-inspiring interface you’ve ever seen (at least I hope not); reason being that this is simply our very first version. We’ll be providing different “skins” like the official MicroMappers skin (below) as well as a skin that allows you to upload your own logo, for example. In the meantime, note that AIDR shows every tweet to at least three different volunteers. And only if each of these 3 volunteers agree on how to classify a given tweet does AIDR take that into consideration when learning. In other words, AIDR wants to ensure that humans are really sure about how to classify a tweet before it decides to learn from that lesson. Incidentally, The MicroMappers smartphone app for the iPhone and Android will be available in the next few weeks. But I digress.
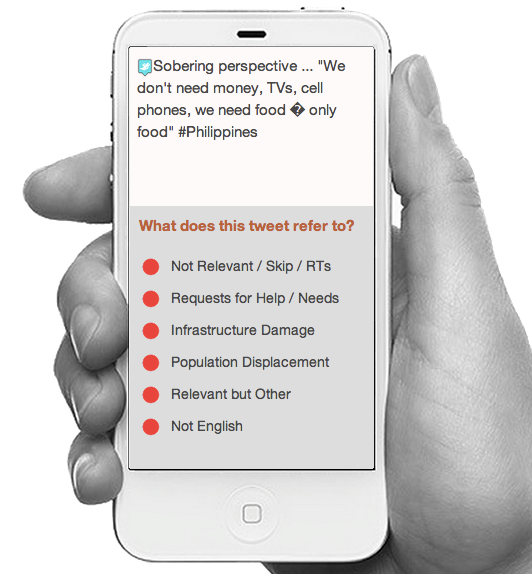
As you and/or your volunteers classify tweets based on the Tags you created, AIDR starts to learn—hence the AI (Artificial Intelligence) in AIDR. AIDR begins to recognize that all the tweets you classified as “Infrastructure Damage” are indeed similar. Once you’ve tagged enough tweets, AIDR will decide that it’s time to leave the nest and fly on it’s own. In other words, it will start to auto-classify incoming tweets in real-time. (At present, AIDR can auto-classify some 30,000 tweets per minute; compare this to the peak rate of 16,000 tweets per minute observed during Hurricane Sandy).
Of course, AIDR’s first solo “flights” won’t always go smoothly. But not to worry, AIDR will let you know when it needs a little help. Every tweet that AIDR auto-tags comes with a Confidence level. That is, AIDR will let you know: “I am 80% sure that I correctly classified this tweet”. If AIDR has trouble with a tweet, i.e., if it’s confidence level is 65% or below, the it will send the tweet to you (and/or your volunteers) so it can learn from how you classify that particular tweet. In other words, the more tweets you classify, the more AIDR learns, and the higher AIDR’s confidence levels get. Fun, huh?
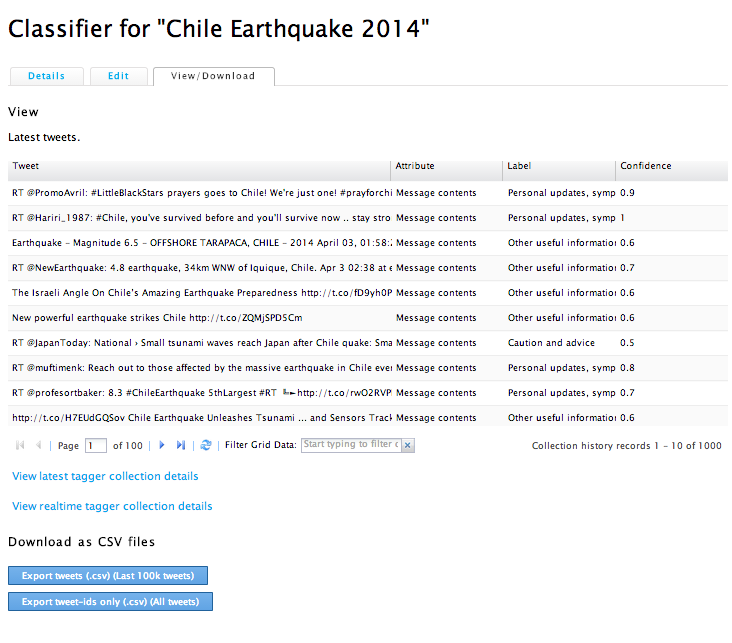
To view the results of the machine tagging, simply click on the View/Download tab, as shown below (click to enlarge). The page shows you the latest tweets that have been auto-tagged along with the Tag label and the confidence score. (Yes, this too is the first version of that interface, we’ll make it more user-friendly in the future, not to worry). In any event, you can download the auto-tagged tweets in a CSV file and also share the download link with your colleagues for analysis and so on. At some point in the future, we hope to provide a simple data visualization output page so that you can easily see interesting data trends.
So that’s basically all there is to it. If you want to learn more about how it all works, you might fancy reading this research paper (PDF). In the meantime, I’ll simply add that you can re-use your Classifiers. If (when?) another earthquake strikes Chile, you won’t have to start from scratch. You can auto-tag incoming tweets immediately with the Classifier you already have. Plus, you’ll be able to share your classifiers with your colleagues and partner organizations if you like. In other words, we’re envisaging an “App Store” of Classifiers based on different hazards and different countries. The more we re-use our Classifiers, the more accurate they will become. Everybody wins.
And voila, that is AIDR (at least our first version). If you’d like to test the platform and/or want the tweets from the Chile Earthquake, simply get in touch!

Note:
- We’re adapting AIDR so that it can also classify text messages (SMS).
- AIDR Classifiers are language specific. So if you speak Spanish, you can create a classifier to tag all Spanish language tweets/SMS that refer to disaster damage, for example. In other words, AIDR does not only speak English : )




