
My Harvard/MIT colleague Todd Mostak wrote his award-winning Master’s Thesis on “Social Media as Passive Polling: Using Twitter and Online Forums to Map Islamism in Egypt.” For this research, Todd evaluated the “potential of Twitter as a source of time-stamped, geocoded public opinion data in the context of the recent popular uprisings in the Middle East.” More specifically, “he explored three ways of measuring a Twitter user’s degree of political Islamism.” Why? Because he wanted to test the long-standing debate on whether Islamism is associated with poverty.

So Todd collected millions of geo-tagged tweets from Egypt over a six month period, which he then aggregated by census district in order to regress proxies for poverty against measures of Islamism drived from the tweets and the users’ social graphs. His findings reveal that “Islamist sentiment seems to be positively correlated with male unemployment, illiteracy, and percentage of land used in agriculture and negatively correlated with percentage of men in their youth aged 15-25. Note that female variables for unemployment and age were statistically insignificant.” As with all research, there are caveats such as the weighting scale used for the variables and questions over the reliability of census variables.
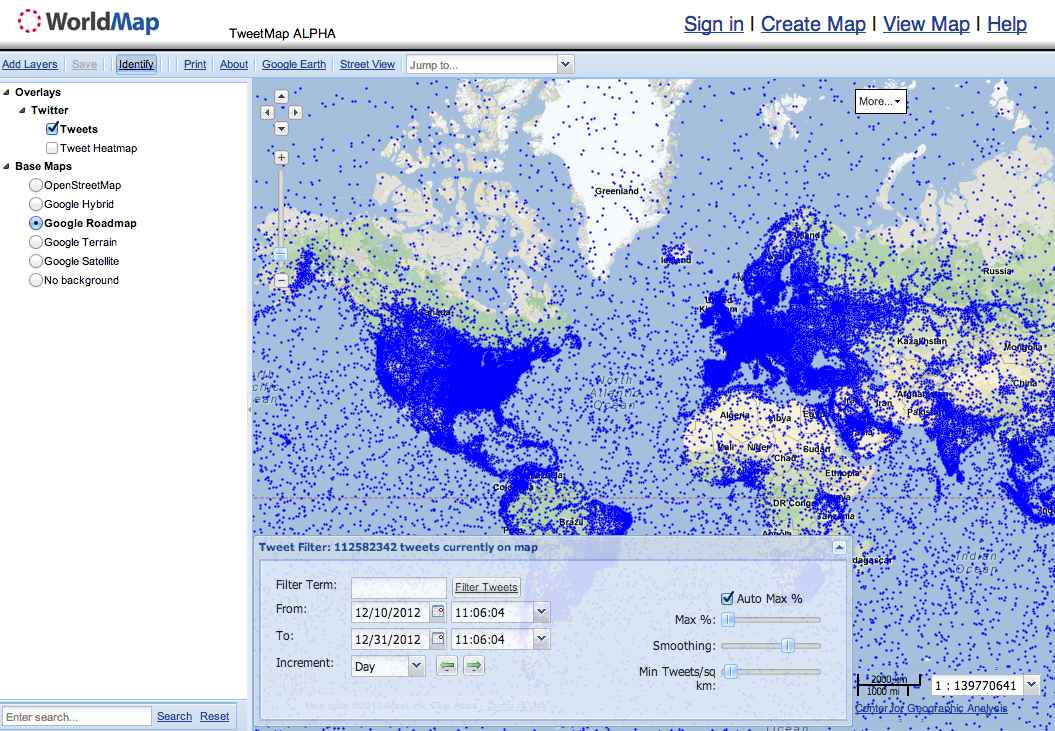
To carry out his graduate research, Todd built a web-enabled database (MapD) powered by a Graphics Processing Units (GPU) to perform real-time querying and visualization of big datasets. He is now working with Harvard’s Center for Geographic Analysis (CGA) to put make this available via a public web interface called Tweetmap. This Big Data streaming and exploration tool presen-tly displays 119 million tweets from 12/10/2012 to 12/31/2012. He is adding 6-7 million new georeferenced tweets per day (but these are not yet publicly available on Tweetmap). According to Todd, the time delay from live tweet to display on the map is about 1 second. Thanks to this GPU-powered approach, he expects that billions of tweets could be displayed in real-time.

As always with impressive projects, no one single person was behind the entire effort. Ben Lewis, who heads the WorldMap initiative at CGA deserves a lot of credit for making Tweetmap a reality. Indeed, Todd collaborated directly with CGA’s Ben Lewis throughout this project and benefited extensively from his expertise. Matt Bertrand (lead developer for CGA) did the WorldMap-side integration of MapD to create the TweetMap interface.
Todd and I recently spoke about integrating his outstanding work on automated live mapping to QCRI’s Twitter Dashboard for Disaster Response. Exciting times. In the meantime, Todd has kindly shared his dataset of 700+ million geotagged tweets for my team and I to analyze. The reason I’m excited about this approach is best explained with this heatmap of the recent snow-storm in the northeastern US. Todd is already using Tweetmap for live crisis mapping. While this system filters by keyword, our Dashboard will use machine learning to provide more specific streams of relevant tweets, some of which could be automatically mapped on Tweetmap. See Todd’s Flickr page for more Tweetmap visuals.

I’m also excited by Todd’s GPU-powered approach for a project I’m exploring with UN and World Bank colleagues. The purpose of that research project is to determine whether socio-economic trends such as poverty and unemployment can be captured via Twitter. Our first case study is Egypt. Depending on the results, we may be able to take it one step further by applying sentiment analysis to real-time, georeferenced tweets to visualize Twitter users’ per-ception vis-a-vis government services—a point of interest for my UN colleagues in Cairo.







