
GDACS, the Global Disaster Alert and Coordination System, sparked my interest in technology and disaster response when it was first launched back in 2004, which is why I’ve referred to GDACS in multiple blog posts since. This near real-time, multi-hazard monitoring platform is a joint initiative between the UN’s Office for the Coordination of Humanitarian Affairs (OCHA) and the European Commission (EC). GDACS serves to consolidate and improve the dissemination of crisis-related information including rapid mathematical analyses of expected disaster impact. The resulting risk information is distributed via Web and auto-mated email, fax and SMS alerts.

I recently had the pleasure of connecting with two new colleagues, Daniel Link and Adam Widera, who are researchers at the University of Muenster’s European Research Center for Information Systems (ERCIS). Daniel and Adam have been working on GDACSmobile, a smartphone app that was initially developed to extend the reach of the GDACS portal. This project originates from a student project supervised by Daniel, Adam along with the Chair of the Center Bernd Hellingrath in cooperation with both Tom de Groeve from the Joint Research Center (JRC) and Minu Kumar Limbu, who is now with UNICEF Kenya.
GDACSmobile is intended for use by disaster responders and the general public, allowing for a combined crowdsourcing and “bounded crowdsourcing” approach to data collection and curation. This bounded approach was a deliberate design feature for GDACSmobile from the outset. I coined the term “bounded crowd-sourcing” four years ago (see this blog post from 2009). The “bounded crowd-sourcing” approach uses “snowball sampling” to grow a crowd of trusted reporters for the collection of crisis information. For example, one invites 5 (or more) trusted local reports to collect relevant information and subsequently ask each of these to invite 5 additional reporters who they fully trust; And so on, and so forth. I’m thrilled to see this term applied in practical applications such GDACSmobile. For more on this approach, please see these blog posts.
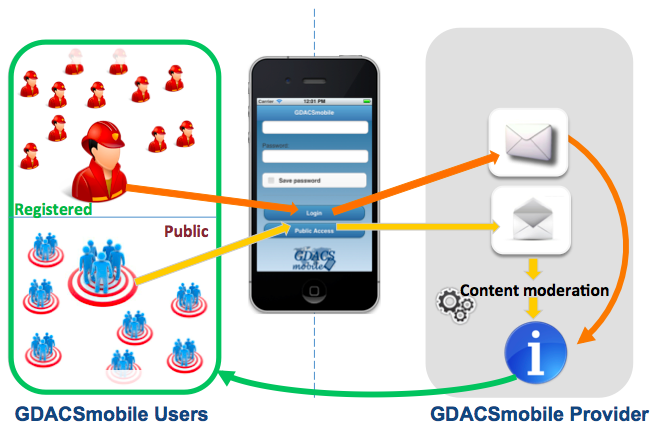
GDACSmobile, which operates on all major mobile smartphones, uses a delibera-tely minimalist approach to situation reporting and can be used to collect info-rmation (via text & image) while offline. The collected data is then automatically transmitted when a connection becomes available. Users can also view & filter data via map view and in list form. Daniel and Adam are considering the addition of an icon-based data-entry interface instead of text-based data-entry since the latter is more cumbersome & time-consuming.

Meanwhile, the server side of GDACSmobile facilitates administrative tasks such as the curation of data submitted by app users and shared on Twitter. Other social media platforms may be added in the future, such as Flickr, to retrieve relevant pictures from disaster-affected areas (similar to GeoFeedia). The server-side moderation feature is used to ensure high data quality standards. But the ERCIS researchers are also open to computational solutions, which is one reason GDACSmobile is not a ‘data island’ and why other systems for computational analysis, microtasking etc., can be used to process the same dataset. The server also “offers a variety of JSON services to allow ‘foreign’ systems to access the data. […] SQL queries can also be used with admin access to the server, and it would be very possible to export tables to spreadsheets […].”
I very much look forward to following GDACSmobile’s progress. Since Daniel and Adam have designed their app to be open and are also themselves open to con-sidering computational solutions, I have already begun to discuss with them our AIDR project (Artificial Intelligence for Disaster Response) project at the Qatar Computing Research Institute (QCRI). I believe that making the ADIR-GDACS interoperable would make a whole lot of sense. Until then, if you’re going to this year’s International Conference on Information Systems for Crisis Response and Management (ISCRAM 2013) in May, then be sure to participate in the workshop (PDF) that Daniel and Adam are running there. The side-event will present the state of the art and future trends of rapid assessment tools to stimulate a conver-sation on current solutions and developments in mobile tech-nologies for post-disaster data analytics and situational awareness. My colleague Dr. Imran Muhammad from QCRI will also be there to present findings from our crisis computing research, so I highly recommend connecting with him.












