As iRevolution readers already know, the application of Information Forensics to social media is one of my primary areas of interest. So I’m always on the lookout for new and related studies, such as this one (PDF), which was just published by colleagues of mine in India. The study by Aditi Gupta et al. analyzes fake content shared on Twitter during the Boston Marathon Bombings earlier this year.

Gupta et al. collected close to 8 million unique tweets posted by 3.7 million unique users between April 15-19th, 2013. The table below provides more details. The authors found that rumors and fake content comprised 29% of the content that went viral on Twitter, while 51% of the content constituted generic opinions and comments. The remaining 20% relayed true information. Interestingly, approximately 75% of fake tweets were propagated via mobile phone devices compared to true tweets which comprised 64% of tweets posted via mobiles.
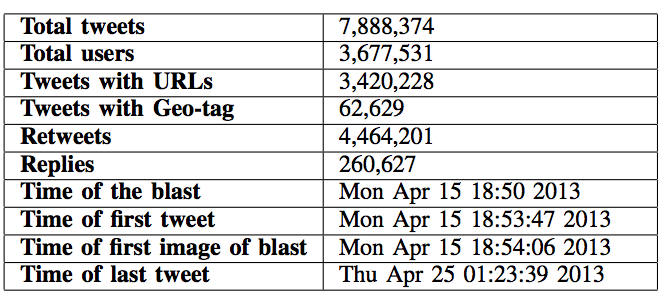
The authors also found that many users with high social reputation and verified accounts were responsible for spreading the bulk of the fake content posted to Twitter. Indeed, the study shows that fake content did not travel rapidly during the first hour after the bombing. Rumors and fake information only goes viral after Twitter users with large numbers of followers start propagating the fake content. To this end, “determining whether some information is true or fake, based on only factors based on high number of followers and verified accounts is not possible in the initial hours.”
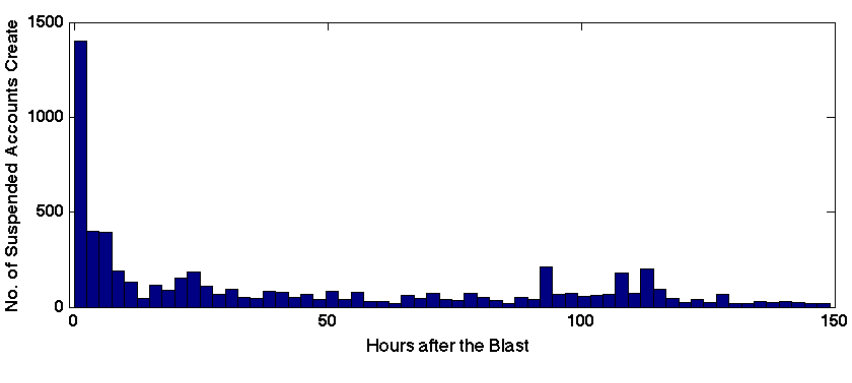
Gupta et al. also identified close to 32,000 new Twitter accounts created between April 15-19 that also posted at least one tweet about the bombings. About 20% (6,073 accounts) of these new accounts were subsequently suspended by Twitter. The authors found that 98.7% of these suspended accounts did not include the word Boston in their names and usernames. They also note that some of these deleted accounts were “quite influential” during the Boston tragedy. The figure below depicts the number of suspended Twitter accounts created in the hours and days following the blast.
The authors also carried out some basic social network analysis of the suspended Twitter accounts. First, they removed from the analysis all suspended accounts that did not interact with each other, which left just 69 accounts. Next, they analyzed the network typology of these 69 accounts, which produced four distinct graph structures: Single Link, Closed Community, Star Typology and Self-Loops. These are displayed in the figure below (click to enlarge).
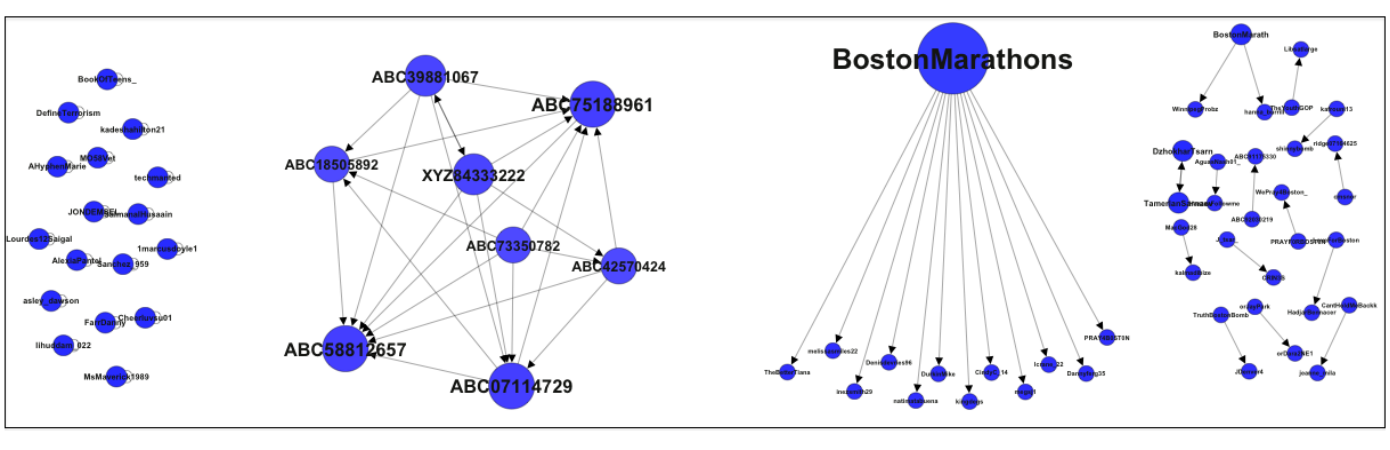
The two most interesting graphs are the Closed Community and Star Typology graphs—the second and third graphs in the figure above.
Closed Community: Users that retweet and mention each other, forming a closed community as indicated by the high closeness centrality values produced by the social network analysis. “All these nodes have similar usernames too, all usernames have the same prefix and only numbers in the suffixes are different. This indicates that either these profiles were created by same or similar minded people for posting common propaganda posts.” Gupta et al. analyzed the content posted by these users and found that all were “tweeting the same propaganda and hate filled tweet.”
Star Typology: Easily mistakable for the authentic “BostonMarathon” Twitter account, the fake account “BostonMarathons” created plenty of confusion. Many users propagated the fake content posted by the BostonMarathons account. As the authors note, “Impersonation or creating fake profiles is a crime that results in identity theft and is punishable by law in many countries.”
The automatic detection of these network structures on Twitter may enable us to detect and counter fake content in the future. In the meantime, my colleagues and I at QCRI are collaborating with Aditi Gupta et al. to develop a “Credibility Plugin” for Twitter based on this analysis and earlier peer-reviewed research carried out by my colleague ChaTo. Stay tuned for updates.

See also:
- Boston Bombings: Analyzing First 1,000 Seconds on Twitter [link]
- Taking the Pulse of the Boston Bombings on Twitter [link]
- Predicting the Credibility of Disaster Tweets Automatically [link]
- Auto-Ranking Credibility of Tweets During Major Events [link]
- Auto-Identifying Fake Images on Twitter During Disasters [link]
- How to Verify Crowdsourced Information from Social Media [link]
- Crowdsourcing Critical Thinking to Verify Social Media [link]