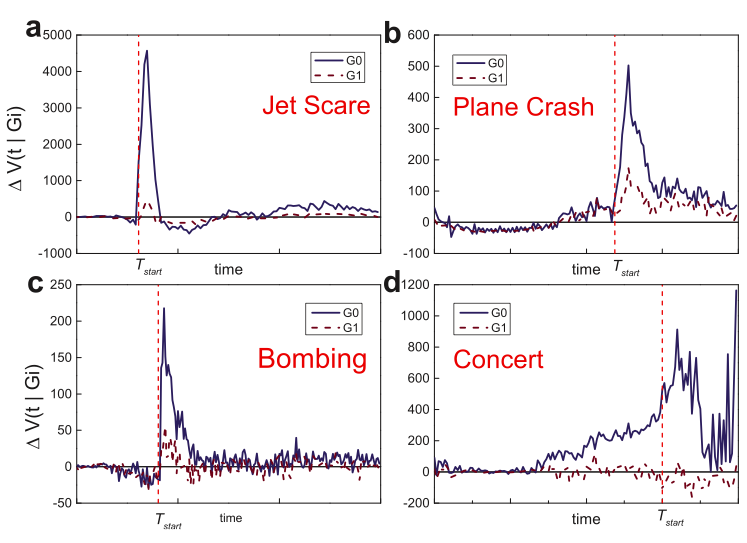
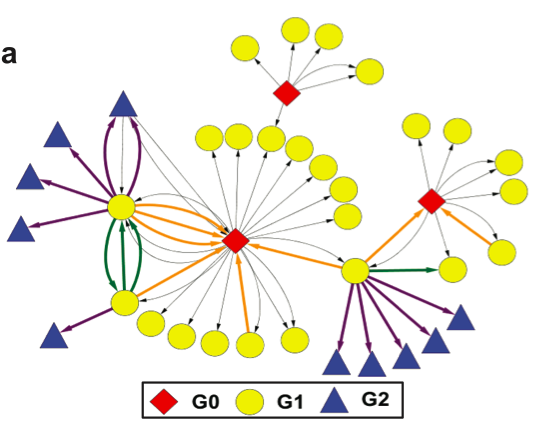
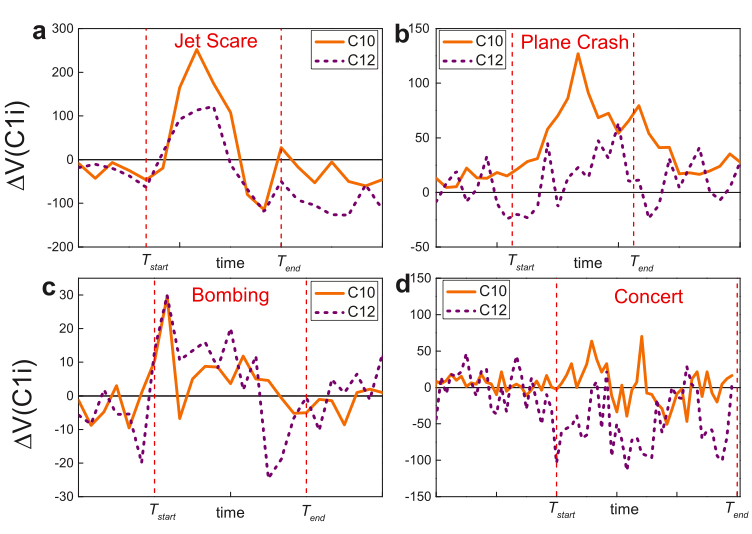
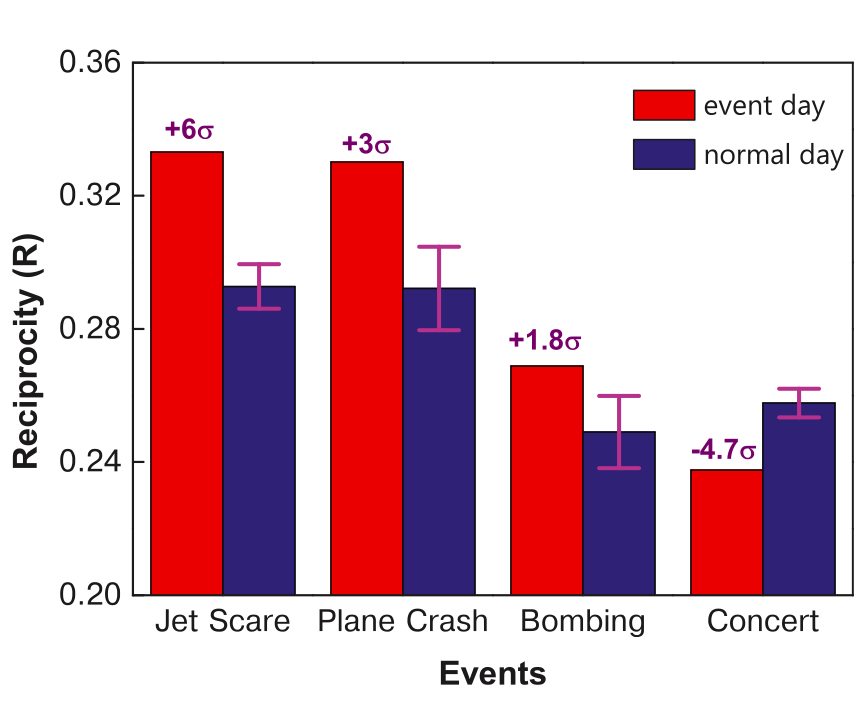
I recently had the distinct honor of being on the opening plenary of the 2012 Skoll World Forum in Oxford. The panel, “Innovation in Times of Flux: Opportunities on the Heels of Crisis” was moderated by Judith Rodin, CEO of the Rockefeller Foundation. I’ve spent the past six years creating linkages between the humanitarian space and technology community, so the conversations we began during the panel prompted me to think more deeply about innovation in the humanitarian industry. Clearly, humanitarian crises have catalyzed a number of important innovations in recent years. At the same time, however, these crises extend the cracks that ultimately reveal the inadequacies of existing organiza-tions, particularly those resistant to change; and “any organization that is not changing is a battle-field monument” (While 1992).
These cracks, or gaps, are increasingly filled by disaster-affected communities themselves thanks in part to the rapid commercialization of communication technology. Question is: will the multi-billion dollar humanitarian industry change rapidly enough to avoid being left in the dustbin of history?
Crises often reveal that “existing routines are inadequate or even counter-productive [since] response will necessarily operate beyond the boundary of planned and resourced capabilities” (Leonard and Howitt 2007). More formally, “the ‘symmetry-breaking’ effects of disasters undermine linearly designed and centralized administrative activities” (Corbacioglu 2006). This may explain why “increasing attention is now paid to the capacity of disaster-affected communities to ‘bounce back’ or to recover with little or no external assistance following a disaster” (Manyena 2006).
But disaster-affected populations have always self-organized in times of crisis. Indeed, first responders are by definition those very communities affected by disasters. So local communities—rather than humanitarian professionals—save the most lives following a disaster (Gilbert 1998). Many of the needs arising after a disaster can often be met and responded to locally. One doesn’t need 10 years of work experience with the UN in Darfur or a Masters degree to know basic first aid or to pull a neighbor out of the rubble, for example. In fact, estimates suggest that “no more than 10% of survival in emergencies can be attributed to external sources of relief aid” (Hilhorst 2004).
This figure may be higher today since disaster-affected communities now benefit from radically wider access to information and communication technologies (ICTs). After all, a “disaster is first of all seen as a crisis in communicating within a community—that is as a difficulty for someone to get informed and to inform other people” (Gilbert 1998). This communication challenge is far less acute today because disaster-affected communities are increasingly digital, and thus more and more the primary source of information communicated following a crisis. Of course, these communities were always sources of information but being a source in an analog world is fundamentally different than being a source of information in the digital age. The difference between “read-only” versus “read-write” comes to mind as an analogy. And so, while humanitarian organiza-tions typically faced a vacuum of information following sudden onset disasters—limited situational awareness that could only be filled by humanitarians on the ground or via established news organizations—one of the major challenges today is the Big Data produced by disaster-affected communities themselves.
Indeed, vacuums are not empty and local communities are not invisible. One could say that disaster-affected communities are joining the quantified self (QS) movement given that they are increasingly quantifying themselves. If inform-ation is power, then the shift of information sourcing and sharing from the select few—the humanitarian professionals—to the masses must also engender a shift in power. Indeed, humanitarians rarely have access to exclusive information any longer. And even though affected populations are increasingly digital, some groups believe that humanitarian organizations have largely failed at commu–nicating with disaster-affected communities. (Naturally, there are important and noteworthy exceptions).

So “Will Twitter Put the UN Out of Business?” (Reuters), or will humanitarian organizations cope with these radical changes by changing themselves and reshaping their role as institutions before it’s too late? Indeed, “a business that doesn’t communicate with its customers won’t stay in business very long—it’ll soon lose track of what its clients want, and clients won’t know what products or services are on offer,” whilst other actors fill the gaps (Reuters). “In the multi-billion dollar humanitarian aid industry, relief agencies are businesses and their beneficiaries are customers. Yet many agencies have muddled along for decades with scarcely a nod towards communicating with the folks they’re supposed to be serving” (Reuters).
The music and news industries were muddling along as well for decades. Today, however, they are facing tremendous pressures and are undergoing radical structural changes—none of them by choice. Of course, it would be different if affected communities were paying for humanitarian services but how much longer do humanitarian organizations have until they feel similar pressures?
Whether humanitarian organizations like it or not, disaster affected communities will increasingly communicate their needs publicly and many will expect a response from the humanitarian industry. This survey carried out by the American Red Cross two years ago already revealed that during a crisis the majority of the public expect a response to needs they communicate via social media. Moreover, they expect this response to materialize within an hour. Humanitarian organizations simply don’t have the capacity to deal with this surge in requests for help, nor are they organizationally structured to do so. But the fact of the matter is that humanitarian organizations have never been capable of dealing with this volume of requests in the first place. So “What Good is Crowd-sourcing When Everyone Needs Help?” (Reuters). Perhaps “crowdsourcing” is finally revealing all the cracks in the system, which may not be a bad thing. Surely by now it is no longer a surprise that many people may be in need of help after a disaster, hence the importance of disaster risk reduction and preparedness.
Naturally, humanitarian organizations could very well chose to continue ignoring calls for help and decide that communicating with disaster affected communities is simply not tenable. In the analog world of the past, the humanitarian industry was protected by the fact that their “clients” did not have a voice because they could not speak out digitally. So the cracks didn’t show. Today, “many traditional humanitarian players see crowdsourcing as an unwelcome distraction at a time when they are already overwhelmed. They worry that the noise-to-signal ration is just too high” (Reuters). I think there’s an important disconnect here worth emphasizing. Crowdsourced information is simply user-generated content. If humanitarians are to ignore user-generated content, then they can forget about two-way communications with disaster-affected communities and drop all the rhetoric. On the other hand, “if aid agencies are to invest time and resources in handling torrents of crowdsourced information in disaster zones, they should be confident it’s worth their while” (Reuters).

This last comment is … rather problematic for several reasons (how’s that for being diplomatic?). First of all, this kind of statement continues to propel the myth that we the West are the rescuers and aid does not start until we arrive (Barrs 2006). Unfortunately, we rarely arrive: how many “neglected crises” and so-called “forgotten emergencies” have we failed to intervene in? This kind of mindset may explain why humanitarian interventions often have the “propensity to follow a paternalistic mode that can lead to a skewing of activities towards supply rather than demand” and towards informing at the expense of listening (Manyena 2006).
Secondly, the assumption that crowdsourced data would be for the exclusive purpose of the humanitarian cavalry is somewhat arrogant and ignores the reality that local communities are by definition the first responders in a crisis. Disaster-affected communities (and Diasporas) are already collecting (and yes crowdsourcing) information to create their own crisis maps in times of need as a forthcoming report shows. And they’ll keep doing this whether or not humanita-rian organizations approve or leverage that information. As my colleague Tim McNamara has noted “Crisis mapping is not simply a technological shift, it is also a process of rapid decentralization of power. With extremely low barriers to entry, many new entrants are appearing in the fields of emergency and disaster response. They are ignoring the traditional hierarchies, because the new entrants perceive that there is something that they can do which benefits others.”
Thirdly, humanitarian organizations are far more open to using free and open source software than they were just two years ago. So the resources required to monitor and map crowdsourced information need not break the bank. Indeed, the Syria Crisis Map uses a free and open source data-mining platform called HealthMap, which has been monitoring some 2,000 English-based sources on a daily basis for months. The technology powering the map itself, Ushahidi, is also free and open source. Moreover, the team behind the project is comprised of just a handful of volunteers doing this in their own free time (for almost an entire year now). And as a result of this initiative, I am collaborating with a colleague from UNDP to pilot HealthMap’s data mining feature for conflict monitoring and peacebuilding purposes.
Fourth, other than UN Global Pulse, humanitarian agencies are not investing time and resources to manage Big (Crisis) Data. Why? Because they have neither the time nor the know-how. To this end, they are starting to “outsource” and indeed “crowdsource” these tasks—just as private sector businesses have been doing for years in order to extend their reach. Anyone actually familiar with this space and developments since Haiti already knows this. The CrisisMappers Network, Standby Volunteer Task Force (SBTF), Humanitarian OpenStreetMap (HOT) and Crisis Commons (CC) are four volunteer/technical networks that have already collaborated actively with a number of humanitarian organizations since Haiti to provide the “surge capacity” requested by the latter; this includes UN OCHA in Libya and Colombia, UNHCR in Somalia and WHO in Libya, to name a few. In fact, these groups even have their own acronym: Volunteer & Technical Communities (V&TCs).
As the former head of OCHA’s Information Services Section (ISS) noted after the SBTF launched the Libya Crisis Map, “Your efforts at tackling a difficult problem have definitely reduced the information overload; sorting through the multitude of signals on the crisis is not easy task” (March 8, 2011). Furthermore, the crowdsourced social media information mapped on the Libya Crisis Map was integrated into official UN OCHA information products. I dare say activating the SBTF was worth OCHA’s while. And it cost the UN a grand total of $0 to benefit from this support.

Credit: Chris Bow
The rapid rise of V&TC’s has catalyzed the launch of the Digital Humanitarian Network (DHN), formerly called the Humanitarian Standby Task Force (H-SBTF). Digital Humanitarians is a network-of-network catalyzed by the UN and comprising some of the most active members of the volunteer & technical co-mmunity. The purpose of the Digital Humanitarian platform (powered by Ning) is to provide a dedicated interface for traditional humanitarian organizations to outsource and crowdsource important information management tasks during and in-between crises. OCHA has also launched the Communities of Interest (COIs) platform to further leverage volunteer engagement in other areas of humanitarian response.
These are not isolated efforts. During the massive Russian fires of 2010, volunteers launched their own citizen-based disaster response agency that was seen by many as more visible and effective than the Kremlin’s response. Back in Egypt, volunteers used IntaFeen.com to crowdsource and coordinate their own humanitarian convoys to Libya, for example. The company LinkedIn has also taken innovative steps to enable the matching of volunteers with various needs. They recently added a “Volunteer and Causes” field to its member profile page, which is now available to 150 million LinkedIn users worldwide. Sparked.com is yet another group engaged in matching volunteers with needs. The company is the world’s first micro-volunteering network, sending challenges to registered volunteers that are targeted to their skill set and the causes that they are most passionate about.
It is not farfetched to envisage how these technologies could be repurposed or simply applied to facilitate and streamline volunteer management following a disaster. Indeed, researchers at the University of Queensland in Australia have already developed a new smart phone app to help mobilize and coordinate volunteer efforts during and following major disasters. The app not only provides information on preparedness but also gives real-time updates on volunteering opportunities by local area. For example, volunteers can register for a variety of tasks including community response to extreme weather events.
Meanwhile, the American Red Cross just launched a Digital Operations Center in partnership with Dell Labs, which allows them to leverage digital volunteers and Dell’s social media monitoring platforms to reduce the noise-to-signal ratio. This is a novel “social media-based operation devoted to humanitarian relief, demonstrating the growing importance of social media in emergency situations.” As part of this center, the Red Cross also “announced a Digital Volunteer program to help respond to question from and provide information to the public during disasters.”

While important challenges do exist, there are many positive externalities to leveraging digital volunteers. As deputy high commissioner of UNHCR noted about this UNHCR-volunteer project in Somalia, these types of projects create more citizen-engagement and raises awareness of humanitarian organizations and projects. This in part explains why UNHCR wants more, not less, engage-ment with digital volunteers. Indeed, these volunteers also develop important skills that will be increasingly sought after by humanitarian organizations recruit-ing for junior full-time positions. Humanitarian organizations are likely to be come smarter and more up to speed on humanitarian technologies and digital humanitarian skills as a result. This change should be embraced.
So given the rise of “self-quantified” disaster-affected communities and digitally empowered volunteer communities, is there a future for traditional humani-tarian organizations? Of course, anyone who suggests otherwise is seriously misguided and out of touch with innovation in the humanitarian space. Twitter will not put the UN out of business. Humanitarian organizations will continue to play some very important roles, especially those relating to logistics and coor-dination. These organizations will continue outsourcing some roles but will also take on some new roles. The issue here is simply one of comparative advantage. Humanitarian organizations used to have a comparative advantage in some areas, but this has shifted for all the reasons described above. So outsourcing in some cases makes perfect sense.
Interestingly, organizations like UN OCHA are also changing some of their own internal information management processes as a result of their collaboration with volunteer networks like the SBTF, which they expect will lead to a number of efficiency gains. Furthermore, OCHA is behind the Digital Humanitarians initiative and has also been developing a check-in app for humanitarian pro-fessionals to use in disaster response—clear signs of innovation and change. Meanwhile, the UK’s Department for International Development (DfID) has just launched a $75+ million fund to leverage new technologies in support of humani-tarian response; this includes mobile phones, satellite imagery, Twitter as well as other social media technologies, digital mapping and gaming technologies. Given that crisis mapping integrates these new technologies and has been at the cutting edge of innovation in the humanitarian space, I’ve invited DfID to participate in this year’s International Conference on Crisis Mapping (ICCM 2012).
In conclusion, and as argued two years ago, the humanitarian industry is shifting towards a more multi-polar system. The rise of new actors, from digitally empowered disaster-affected communities to digital volunteer networks, has been driven by the rapid commercialization of communication technology—particularly the mobile phone and social networking platforms. These trends are unlikely to change soon and crises will continue to spur innovations in this space. This does not mean that traditional humanitarian organizations are becoming obsolete. Their roles are simply changing and this change is proof that they are not battlefield monuments. Of course, only time will tell whether they change fast enough.