Both humanitarian and development organizations are completely unprepared to deal with the rise of “Big Crisis Data” & “Big Development Data.” But many still hope that Big Data is but an illusion. Not so, as I’ve already blogged here, here and here. This explains why I’m on a quest to tame the Big Data Beast. Enter Zooniverse. I’ve been a huge fan of Zooniverse for as long as I can remember, and certainly long before I first mentioned them in this post from two years ago. Zooniverse is a citizen science platform that evolved from GalaxyZoo in 2007. Today, Zooniverse “hosts more than a dozen projects which allow volunteers to participate in scientific research” (1). So, why do I have a major “techie crush” on Zooniverse?

Oh let me count the ways. Zooniverse interfaces are absolutely gorgeous, making them a real pleasure to spend time with; they really understand user-centered design and motivations. The fact that Zooniverse is conversent in multiple disciplines is incredibly attractive. Indeed, the platform has been used to produce rich scientific data across multiple fields such as astronomy, ecology and climate science. Furthermore, this citizen science beauty has a user-base of some 800,000 registered volunteers—with an average of 500 to 1,000 new volunteers joining every day! To place this into context, the Standby Volunteer Task Force (SBTF), a digital humanitarian group has about 1,000 volunteers in total. The open source Zooniverse platform also scales like there’s no tomorrow, enabling hundreds of thousands to participate on a single deployment at any given time. In short, the software supporting these pioneering citizen science projects is well tested and rapidly customizable.
At the heart of the Zooniverse magic is microtasking. If you’re new to microtasking, which I often refer to as “smart crowdsourcing,” this blog post provides a quick introduction. In brief, Microtasking takes a large task and breaks it down into smaller microtasks. Say you were a major (like really major) astro-nomy buff and wanted to tag a million galaxies based on whether they are spiral or elliptical galaxies. The good news? The kind folks at the Sloan Digital Sky Survey have already sent you a hard disk packed full of telescope images. The not-so-good news? A quick back-of-the-envelope calculation reveals it would take 3-5 years, working 24 hours/day and 7 days/week to tag a million galaxies. Ugh!

But you’re a smart cookie and decide to give this microtasking thing a go. So you upload the pictures to a microtasking website. You then get on Facebook, Twitter, etc., and invite (nay beg) your friends (and as many strangers as you can find on the suddenly-deserted digital streets), to help you tag a million galaxies. Naturally, you provide your friends, and the surprisingly large number good digital Samaritans who’ve just show up, with a quick 2-minute video intro on what spiral and elliptical galaxies look like. You explain that each participant will be asked to tag one galaxy image at a time by simply by clicking the “Spiral” or “Elliptical” button as needed. Inevitably, someone raises their hands to ask the obvious: “Why?! Why in the world would anyone want to tag a zillion galaxies?!”
Well, only cause analyzing the resulting data could yield significant insights that may force a major rethink of cosmology and our place in the Universe. “Good enough for us,” they say. You breathe a sigh of relief and see them off, cruising towards deep space to bolding go where no one has gone before. But before you know it, they’re back on planet Earth. To your utter astonishment, you learn that they’re done with all the tagging! So you run over and check the data to see if they’re pulling your leg; but no, not only are 1 million galaxies tagged, but the tags are highly accurate as well. If you liked this little story, you’ll be glad to know that it happened in real life. GalaxyZoo, as the project was called, was the flash of brilliance that ultimately launched the entire Zooniverse series.

No, the second Zooniverse project was not an attempt to pull an Oceans 11 in Las Vegas. One of the most attractive features of many microtasking platforms such as Zooniverse is quality control. Think of slot machines. The only way to win big is by having three matching figures such as the three yellow bells in the picture above (righthand side). Hit the jackpot and the coins will flow. Get two out three matching figures (lefthand side), and some slot machines may toss you a few coins for your efforts. Microtasking uses the same approach. Only if three participants tag the same picture of a galaxy as being a spiral galaxy does that data point count. (Of course, you could decide to change the requirement from 3 volunteers to 5 or even 20 volunteers). This important feature allows micro-tasking initiatives to ensure a high standard of data quality, which may explain why many Zooniverse projects have resulted in major scientific break-throughs over the years.
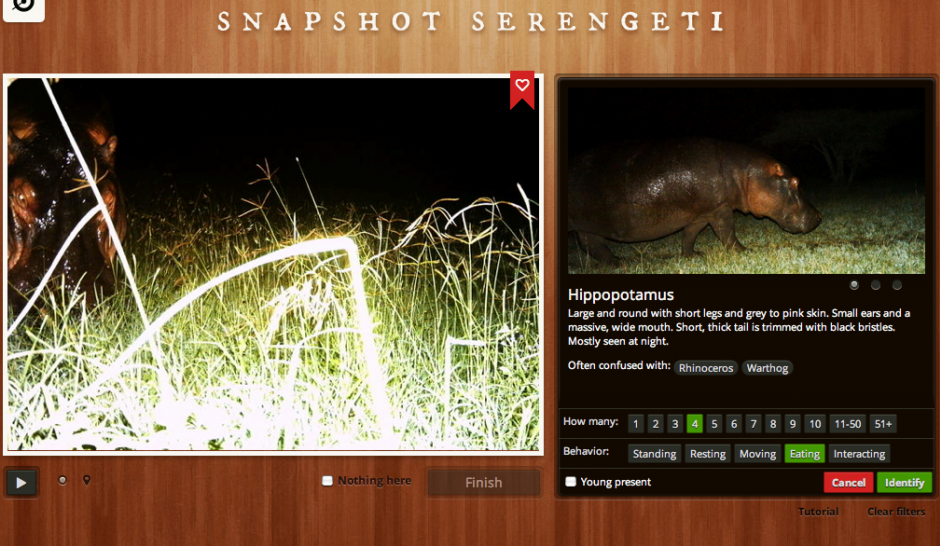
The Zooniverse team is currently running 15 projects, with several more in the works. One of the most recent Zooniverse deployments, Planet Four, received some 15,000 visitors within the first 60 seconds of being announced on BBC TV. Guess how many weeks it took for volunteers to tag over 2,000,0000 satellite images of Mars? A total of 0.286 weeks, i.e., forty-eight hours! Since then, close to 70,000 volunteers have tagged and traced well over 6 million Martian “dunes.” For their Andromeda Project, digital volunteers classified over 7,500 star clusters per hour, even though there was no media or press announce-ment—just one newsletter sent to volunteers. Zooniverse de-ployments also involve tagging earth-based pictures (in contrast to telescope imagery). Take this Serengeti Snapshot deployment, which invited volunteers to classify animals using photographs taken by 225 motion-sensor cameras in Tanzania’s Serengeti National Park. Volunteers swarmed this project to the point that there are no longer any pictures left to tag! So Zooniverse is eagerly waiting for new images to be taken in Serengeti and sent over.

One of my favorite Zooniverse features is Talk, an online discussion tool used for all projects to provide a real-time interface for volunteers and coordinators, which also facilitates the rapid discovery of important features. This also allows for socializing, which I’ve found to be particularly important with digital humanitarian deployments (such as these). One other major advantage of citizen science platforms like Zooniverse is that they are very easy to use and therefore do not require extensive prior-training (think slot machines). Plus, participants get to learn about new fields of science in the process. So all in all, Zooniverse makes for a great date, which is why I recently reached out to the team behind this citizen science wizardry. Would they be interested in going out (on a limb) to explore some humanitarian (and development) use cases? “Why yes!” they said.
Microtasking platforms have already been used in disaster response, such as MapMill during Hurricane Sandy, Tomnod during the Somali Crisis and CrowdCrafting during Typhoon Pablo. So teaming up with Zooniverse makes a whole lot of sense. Their microtasking software is the most scalable one I’ve come across yet, it is open source and their 800,000 volunteer user-base is simply unparalleled. If Zooniverse volunteers can classify 2 million satellite images of Mars in 48 hours, then surely they can do the same for satellite images of disaster-affected areas on Earth. Volunteers responding to Sandy created some 80,000 assessments of infrastructure damage during the first 48 hours alone. It would have taken Zooniverse just over an hour. Of course, the fact that the hurricane affected New York City and the East Coast meant that many US-based volunteers rallied to the cause, which may explain why it only took 20 minutes to tag the first batch of 400 pictures. What if the hurricane had hit a Caribbean instead? Would the surge of volunteers may have been as high? Might Zooniverse’s 800,000+ standby volunteers also be an asset in this respect?

Clearly, there is huge potential here, and not only vis-a-vis humanitarian use-cases but development one as well. This is precisely why I’ve already organized and coordinated a number of calls with Zooniverse and various humanitarian and development organizations. As I’ve been telling my colleagues at the United Nations, World Bank and Humanitarian OpenStreetMap, Zooniverse is the Ferrari of Microtasking, so it would be such a big shame if we didn’t take it out for a spin… you know, just a quick test-drive through the rugged terrains of humanitarian response, disaster preparedness and international development.

Postscript: As some iRevolution readers may know, I am also collaborating with the outstanding team at CrowdCrafting, who have also developed a free & open-source microtasking platform for citizen science projects (also for disaster response here). I see Zooniverse and CrowCrafting as highly syner-gistic and complementary. Because CrowdCrafting is still in early stages, they fill a very important gap found at the long tail. In contrast, Zooniverse has been already been around for half-a-decade and can caters to very high volume and high profile citizen science projects. This explains why we’ll all be getting on a call in the very near future.