Update: We’re developing & launching MicroFilters to improve MicroMappers.
About 47 hours ago, the UN Office for the Coordination of Humanitarian Affairs (OCHA) activated the Digital Humanitarian Network (DHN) in response to the Pakistan Earthquake. The activation request was for 48 hours, so the deployment will soon phase out. As already described here, the Standby Volunteer Task Force (SBTF) teamed up with QCRI to carry out an early test of MicroMappers, which was not set to launch until next month. This post shares some initial thoughts on how the test went along with preliminary results.

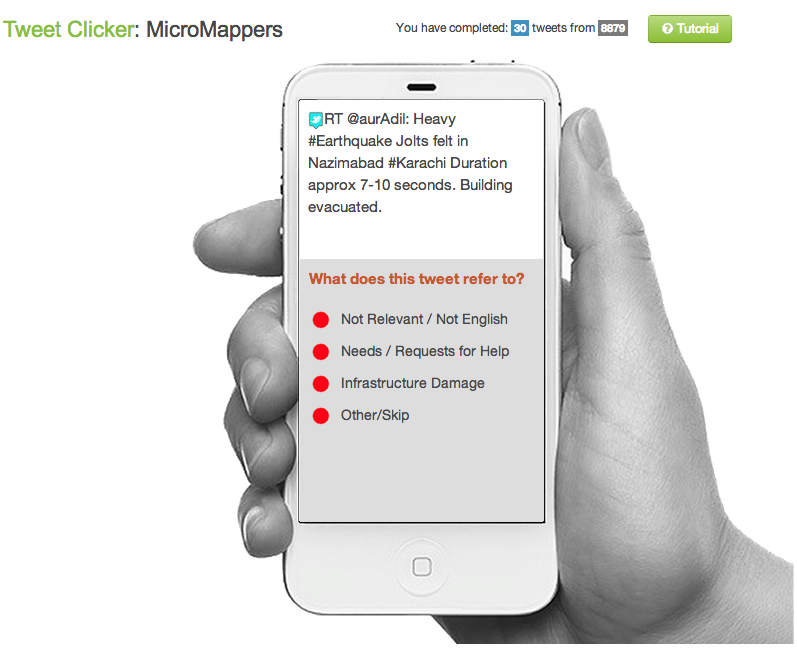
During ~40 hours, 109 volunteers from the SBTF and the public tagged just over 30,000 tweets that were posted during the first 36 hours or so after the quake. We were able to automatically collect these tweets thanks to our partnership with GNIP and specifically filtered for said tweets using half-a-dozen hashtags. Given the large volume of tweets collected, we did not require that each tweet be tagged at least 3 times by individual volunteers to ensure data quality control. Out of these 30,000+ tweets, volunteers tagged a total of 177 tweets as noting needs or infrastructure damage. A review of these tweets by the SBTF concluded that none were actually informative or actionable.
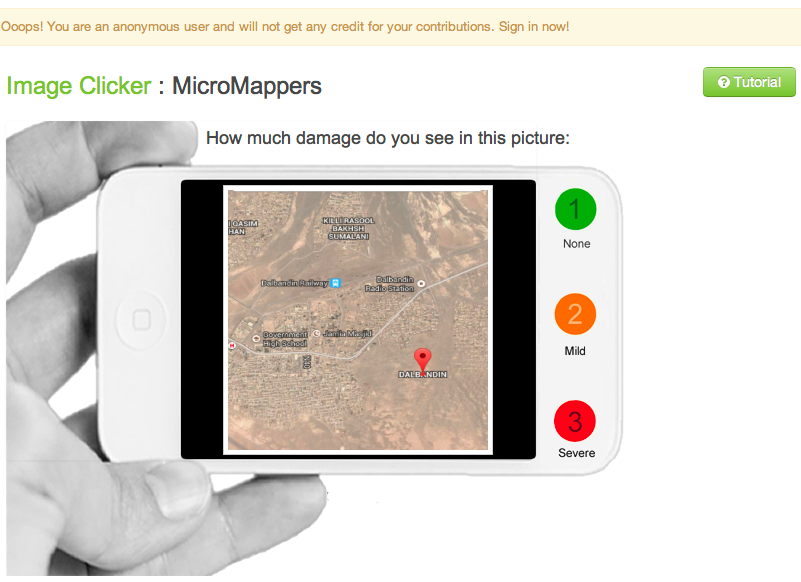
Just over 350 pictures were tweeted in the aftermath of the earthquake. These were uploaded to the ImageClicker for tagging purposes. However, none of the pictures captured evidence of infrastructure damage. In fact, the vast majority were unrelated to the earthquake. This was also true of pictures published in news articles. Indeed, we used an automated algorithm to identify all tweets with links to news articles; this algorithm would then crawl these articles for evidence of images. We found that the vast majority of these automatically extracted pictures were related to politics rather than infrastructure damage.

A few preliminary thoughts and reflections from this first test of MicroMappers. First, however, a big, huge, gigantic thanks to my awesome QCRI team: Ji Lucas, Imran Muhammad and Kiran Garimella; to my outstanding colleagues on the SBTF Core Team including but certainly not limited to Jus Mackinnon, Melissa Elliott, Anahi A. Iaccuci, Per Aarvik & Brendan O’Hanrahan (bios here); to the amazing SBTF volunteers and members of the general public who rallied to tag tweets and images—in particular our top 5 taggers: Christina KR, Leah H, Lubna A, Deborah B and Joyce M! Also bravo to volunteers in the Netherlands, UK, US and Germany for being the most active MicroMappers; and last but certainly not least, big, huge and gigantic thanks to Andrew Ilyas for developing the algorithms to automatically identify pictures and videos posted to Twitter.
So what did we learn over the past 48 hours? First, the disaster-affected region is a remote area of south-western Pakistan with a very light social media footprint, so there was practically no user-generated content directly relevant to needs and damage posted on Twitter during the first 36 hours. In other words, there were no needles to be found in the haystack of information. This is in stark contrast to our experience when we carried out a very similar operation following Typhoon Pablo in the Philippines. Obviously, if there’s little to no social media footprint in a disaster-affected area, then monitoring social media is of no use at all to anyone. Note, however, that MicroMappers could also be used to tag 30,000+ text messages (SMS). (Incidentally, since the earthquake struck around 12noon local time, there was only about 18 hours of daylight during the 36-hour period for which we collected the tweets).
Second, while the point of this exercise was not to test our pre-processing filters, it was clear that the single biggest problem was ultimately with the filtering. Our goal was to upload as many tweets as possible to the Clickers and stress-test the apps. So we only filtered tweets using a number of general hashtags such as #Pakistan. Furthermore, we did not filter out any retweets, which probably accounted for 2/3 of the data, nor did we filter by geography to ensure that we were only collecting and thus tagging tweets from users based in Pakistan. This was a major mistake on our end. We were so pre-occupied with testing the actual Clickers that we simply did not pay attention to the pre-processing of tweets. This was equally true of the images uploaded to the ImageClicker.

So where do we go from here? Well we have pages and pages worth of feedback to go through and integrate in the next version of the Clickers. For me, one of the top priorities is to optimize our pre-processing algorithms and ensure that the resulting output can be automatically uploaded to the Clickers. We have to refine our algorithms and make damned sure that we only upload unique tweets and images to our Clickers. At most, volunteers should not see the same tweet or image more than 3 times for verification purposes. We should also be more careful with our hashtag filtering and also consider filtering by geography. Incidentally, when our free & open source AIDR platform becomes operational in November, we’ll also have the ability to automatically identify tweets referring to needs, reports of damage, and much, much more.
In fact, AIDR was also tested for the very first time. SBTF volunteers tagged about 1,000 tweets, and just over 130 of the tags enabled us to create an accurate classifier that can automatically identify whether a tweet is relevant for disaster response efforts specifically in Pakistan (80% accuracy). Now, we didn’t apply this classifier on incoming tweets because AIDR uses streaming Twitter data, not static, archived data which is what we had (in the form of CSV files). In any event, we also made an effort to create classifiers for needs and infrastructure damage but did not get enough tags to make these accurate enough. Typically, we need a minimum of 20 or so tags (i.e., examples of actual tweets referring to needs or damage). The more tags, the more accurate the classifier.
The reason there were so few tags, however, is because there were very few to no informative tweets referring to needs or infrastructure damage during the first 36 hours. In any event, I believe this was the very first time that a machine learning classifier was crowdsourced for disaster response purposes. In the future, we may want to first crowdsource a machine learning classifier for disaster relevant tweets and then upload the results to MicroMappers; this would reduce the number of unrelated tweets displayed on a TweetClicker.
As expected, we have also received a lot of feedback vis-a-vis user experience and the user interface of the Clickers. Speed is at the top of the list. That is, making sure that once I’ve clicked on a tweet/image, the next tweet/image automatically appears. At times, I had to wait more than 20 seconds for the next item to load. We also need to add more progress bars such as the number of tweets or images that remain to be tagged—a countdown display, basically. I could go on and on, frankly, but hopefully these early reflections are informative and useful to others developing next-generation humanitarian technologies. In sum, there is a lot of work to be done still. Onwards!