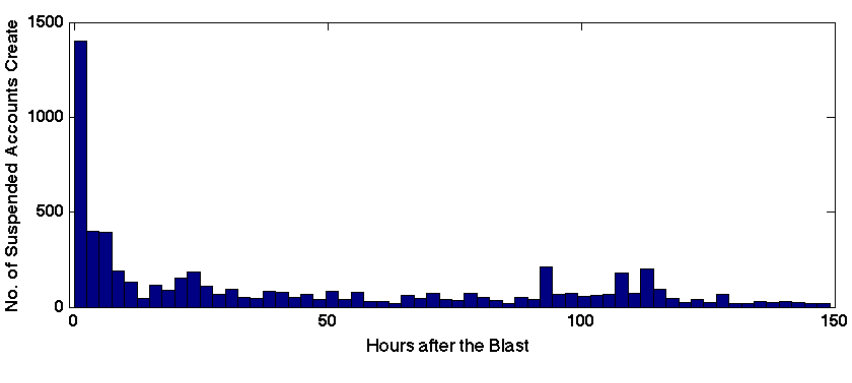
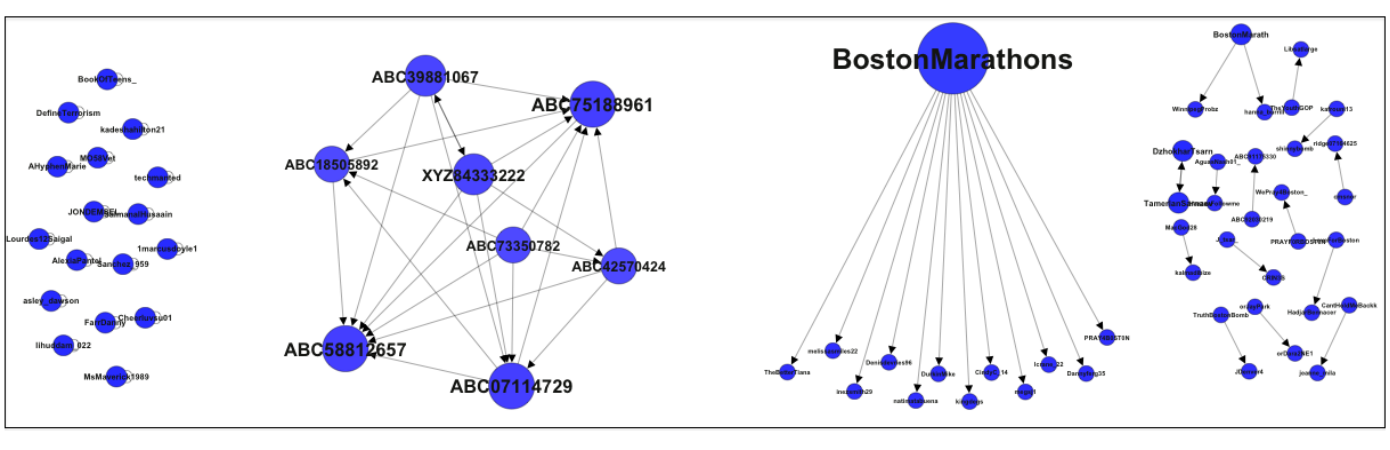
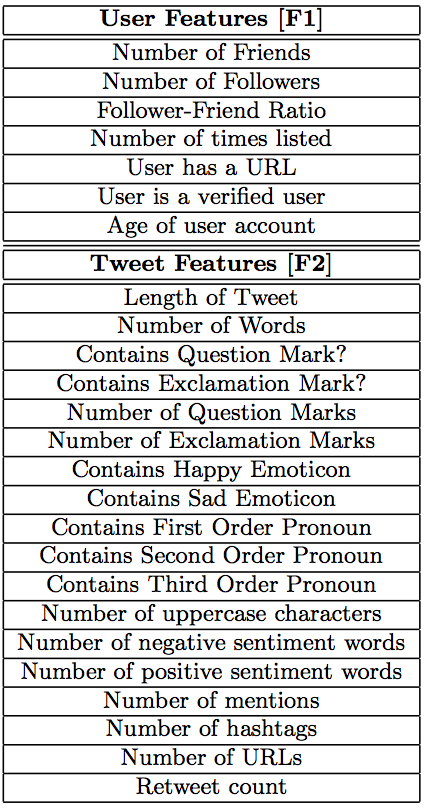
My new colleague Professor Yasuaki Sakamoto at the Stevens Institute of Tech-nology (SIT) has been carrying out intriguing research on the spread of rumors via social media, particularly on Twitter and during crises. In his latest research, “Toward a Social-Technological System that Inactivates False Rumors through the Critical Thinking of Crowds,” Yasu uses behavioral psychology to under-stand why exposure to public criticism changes rumor-spreading behavior on Twitter during disasters. This fascinating research builds very nicely on the excellent work carried out by my QCRI colleague ChaTo who used this “criticism dynamic” to show that the credibility of tweets can be predicted (by topic) with-out analyzing their content. Yasu’s study also seeks to find the psychological basis for the Twitter’s self-correcting behavior identified by ChaTo and also John Herman who described Twitter as a “Truth Machine” during Hurricane Sandy.

Twitter is still a relatively new platform, but the existence and spread of false rumors is certainly not. In fact, a very interesting study dated 1950 found that “in the past 1,000 years the same types of rumors related to earthquakes appear again and again in different locations.” Early academic studies on the spread of rumors revealed that “that psychological factors, such as accuracy, anxiety, and impor-tance of rumors, affect rumor transmission.” One such study proposed that the spread of a rumor “will vary with the importance of the subject to the individuals concerned times the ambiguity of the evidence pertaining to the topic at issue.” Later studies added “anxiety as another key element in rumormongering,” since “the likelihood of sharing a rumor was related to how anxious the rumor made people feel. At the same time, however, the literature also reveals that counter-measures do exist. Critical thinking, for example, decreases the spread of rumors. The literature defines critical thinking as “reasonable reflective thinking focused on deciding what to believe or do.”
“Given the growing use and participatory nature of social media, critical thinking is considered an important element of media literacy that individuals in a society should possess.” Indeed, while social media can “help people make sense of their situation during a disaster, social media can also become a rumor mill and create social problems.” As discussed above, psychological factors can influence rumor spreading, particularly when experiencing stress and mental pressure following a disaster. Recent studies have also corroborated this finding, confirming that “differences in people’s critical thinking ability […] contributed to the rumor behavior.” So Yasu and his team ask the following interesting question: can critical thinking be crowdsourced?

“Not everyone needs to be a critical thinker all the time,” writes Yasu et al. As long as some individuals are good critical thinkers in a specific domain, their timely criticisms can result in an emergent critical thinking social system that can mitigate the spread of false information. This goes to the heart of the self-correcting behavior often observed on social media and Twitter in particular. Yasu’s insight also provides a basis for a bounded crowdsourcing approach to disaster response. More on this here, here and here.
“Related to critical thinking, a number of studies have paid attention to the role of denial or rebuttal messages in impeding the transmission of rumor.” This is the more “visible” dynamic behind the self-correcting behavior observed on Twitter during disasters. So while some may spread false rumors, others often try to counter this spread by posting tweets criticizing rumor-tweets directly. The following questions thus naturally arise: “Are criticisms on Twitter effective in mitigating the spread of false rumors? Can exposure to criticisms minimize the spread of rumors?”
Yasu and his colleagues set out to test the following hypotheses: Exposure to criticisms reduces people’s intent to spread rumors; which mean that ex-posure to criticisms lowers perceived accuracy, anxiety, and importance of rumors. They tested these hypotheses on 87 Japanese undergraduate and grad-uate students by using 20 rumor-tweets related to the 2011 Japan Earthquake and 10 criticism-tweets that criticized the corresponding rumor-tweets. For example:
Rumor-tweet: “Air drop of supplies is not allowed in Japan! I though it has already been done by the Self- Defense Forces. Without it, the isolated people will die! I’m trembling with anger. Please retweet!”
Criticism-tweet: “Air drop of supplies is not prohibited by the law. Please don’t spread rumor. Please see 4-(1)-丸 4-エ.”
The researchers found that “exposing people to criticisms can reduce their intent to spread rumors that are associated with the criticisms, providing support for the system.” In fact, “Exposure to criticisms increased the proportion of people who stop the spread of rumor-tweets approximately 1.5 times [150%]. This result indicates that whether a receiver is exposed to rumor or criticism first makes a difference in her decision to spread the rumor. Another interpretation of the result is that, even if a receiver is exposed to a number of criticisms, she will benefit less from this exposure when she sees rumors first than when she sees criticisms before rumors.”

Findings also revealed three psychological factors that were related to the differences in the spread of rumor-tweets: one’s own perception of the tweet’s accuracy, the anxiety cause by the tweet, and the tweet’s perceived importance. The results also indicate that “exposure to criticisms reduces the perceived accuracy of the succeeding rumor-tweets, paralleling the findings by previous research that refutations or denials decrease the degree of belief in rumor.” In addition, the perceived accuracy of criticism-tweets by those exposed to rumors first was significantly higher than the criticism-first group. The results were similar vis-à-vis anxiety. “Seeing criticisms before rumors reduced anxiety associated with rumor-tweets relative to seeing rumors first. This result is also consistent with previous research findings that denial messages reduce anxiety about rumors. Participants in the criticism-first group also perceived rumor-tweets to be less important than those in the rumor-first group.” The same was true vis-à-vis the perceived importance of a tweet. That said, “When the rumor-tweets are perceived as more accurate, the intent to spread the rumor-tweets are stronger; when rumor-tweets cause more anxiety, the intent to spread the rumor-tweets is stronger; when the rumor-tweets are perceived as more im-portance, the intent to spread the rumor-tweets is also stronger.”
So how do we use these findings to enhance the critical thinking of crowds and design crowdsourced verification platforms such as Verily? Ideally, such a platform would connect rumor tweets with criticism-tweets directly. “By this design, information system itself can enhance the critical thinking of the crowds.” That said, the findings clearly show that sequencing matters—that is, being exposed to rumor tweets first vs criticism tweets first makes a big differ-ence vis-à-vis rumor contagion. The purpose of a platform like Verily is to act as a repo-sitory for crowdsourced criticisms and rebuttals; that is, crowdsourced critical thinking. Thus, the majority of Verily users would first be exposed to questions about rumors, such as: “Has the Vincent Thomas Bridge in Los Angeles been destroyed by the Earthquake?” Users would then be exposed to the crowd-sourced criticisms and rebuttals.
In conclusion, the spread of false rumors during disasters will never go away. “It is human nature to transmit rumors under uncertainty.” But social-technological platforms like Verily can provide a repository of critical thinking and ed-ucate users on critical thinking processes themselves. In this way, we may be able to enhance the critical thinking of crowds.

See also:
- Wiki on Truthiness resources (Link)
- How to Verify and Counter Rumors in Social Media (Link)
- Social Media and Life Cycle of Rumors during Crises (Link)
- How to Verify Crowdsourced Information from Social Media (Link)
- Analyzing the Veracity of Tweets During a Crisis (Link)
- Crowdsourcing for Human Rights: Challenges and Opportunities for Information Collection & Verification (Link)
- The Crowdsourcing Detective: Crisis, Deception and Intrigue in the Twittersphere (Link)