I’ve been looking forward to blogging about my team’s latest research on crisis computing for months; the delay being due to the laborious process of academic publishing, but I digress. I’m now able to make their findings public. The goal of their latest research was to “understand what affected populations, response agencies and other stakeholders can expect—and not expect—from [crisis tweets] in various types of disaster situations.”

As my colleagues rightly note, “Anecdotal evidence suggests that different types of crises elicit different reactions from Twitter users, but we have yet to see whether this is in fact the case.” So they meticulously studied 26 crisis-related events between 2012-2013 that generated significant activity on twitter. The lead researcher on this project, my colleague & friend Alexandra Olteanu from EPFL, also appears in my new book.
Alexandra and team first classified crisis related tweets based on the following categories (each selected based on previous research & peer-reviewed studies):

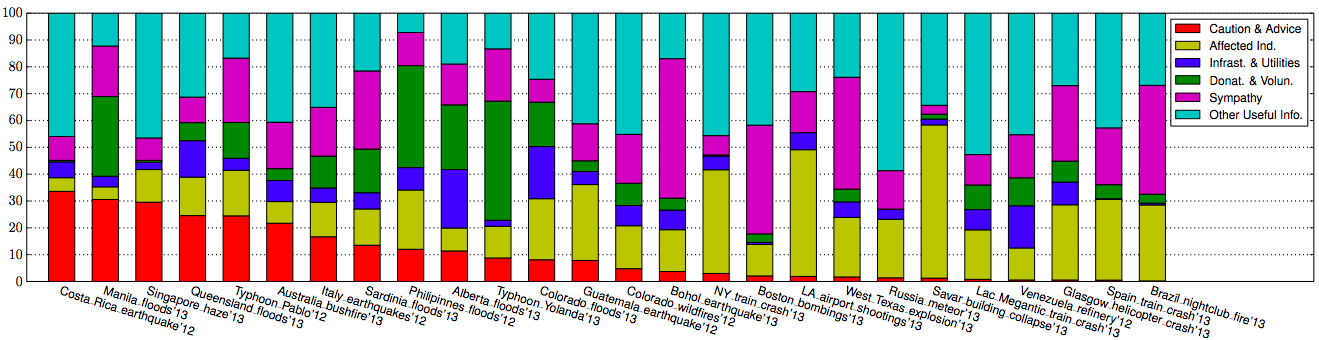
Written in long form: Caution & Advice; Affected Individuals; Infrastructure & Utilities; Donations & Volunteering; Sympathy & Emotional Support, and Other Useful Information. Below are the results of this analysis sorted by descending proportion of Caution & Advice related tweets (click to enlarge).

The category with the largest number of tweets is “Other Useful Info.” On average 32% of tweets fall into this category (minimum 7%, maximum 59%). Interestingly, it appears that most crisis events that are spread over a relatively large geographical area (i.e., they are diffuse), tend to be associated with the lowest number of “Other” tweets. As my QCRI rightly colleagues note, “it is potentially useful to know that this type of tweet is not prevalent in the diffused events we studied.”
Tweets relating to Sympathy and Emotional Support are present in each of the 26 crises. On average, these account for 20% of all tweets. “The 4 crises in which the messages in this category were more prevalent (above 40%) were all instantaneous disasters.” This finding may imply that “people are more likely to offer sympathy when events […] take people by surprise.”
On average, 20% of tweets in the 26 crises relate to Affected Individuals. “The 5 crises with the largest proportion of this type of information (28%–57%) were human-induced, focalized, and instantaneous. These 5 events can also be viewed as particularly emotionally shocking.”
Tweets related to Donations & Volunteering accounted for 10% of tweets on average. “The number of tweets describing needs or offers of goods and services in each event varies greatly; some events have no mention of them, while for others, this is one of the largest information categories. “
Caution and Advice tweets constituted on average 10% of all tweets in a given crisis. The results show a “clear separation between human-induced hazards and natural: all human induced events have less caution and advice tweets (0%–3%) than all the events due to natural hazards (4%–31%).”
Finally, tweets related to Infrastructure and Utilities represented on average 7% of all tweets posted in a given crisis. The disasters with the highest number of such tweets tended to be flood situations.
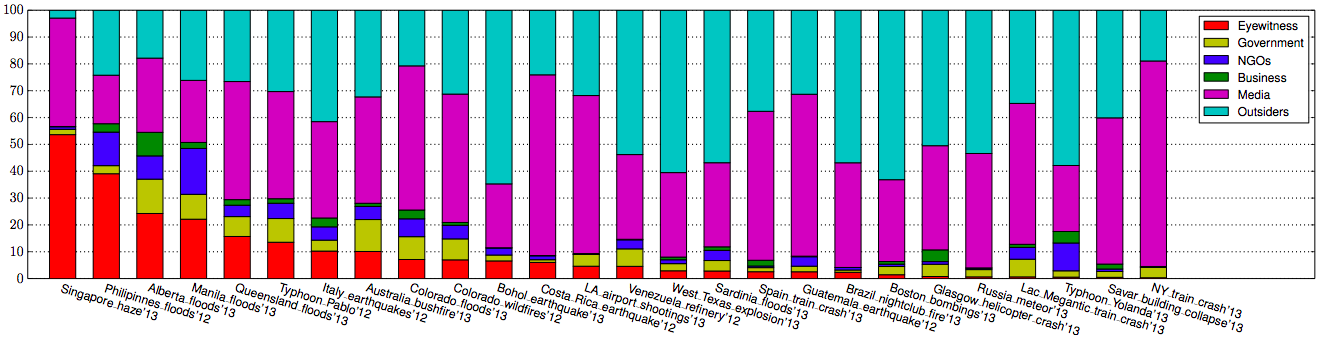
In addition to the above analysis, Alexandra et al. also categorized tweets by their source:

The results depicted below (click to enlarge) are sorted by descending order of eyewitness tweets.

On average, about 9% of tweets generated during a given crises were written by Eyewitnesses; a figure that increased to 54% for the haze crisis in Singapore. “In general, we find a larger proportion of eyewitness accounts during diffused disasters caused by natural hazards.”
Traditional and/or Internet Media were responsible for 42% of tweets on average. ” The 6 crises with the highest fraction of tweets coming from a media source (54%–76%) are instantaneous, which make “breaking news” in the media.
On average, Outsiders posted 38% of the tweets in a given crisis while NGOs were responsible for about 4% of tweets and Governments 5%. My colleagues surmise that these low figures are due to the fact that both NGOs and governments seek to verify information before they release it. The highest levels of NGO and government tweets occur in response to natural disasters.
Finally, Businesses account for 2% of tweets on average. The Alberta floods of 2013 saw the highest proportion (9%) of tweets posted by businesses.
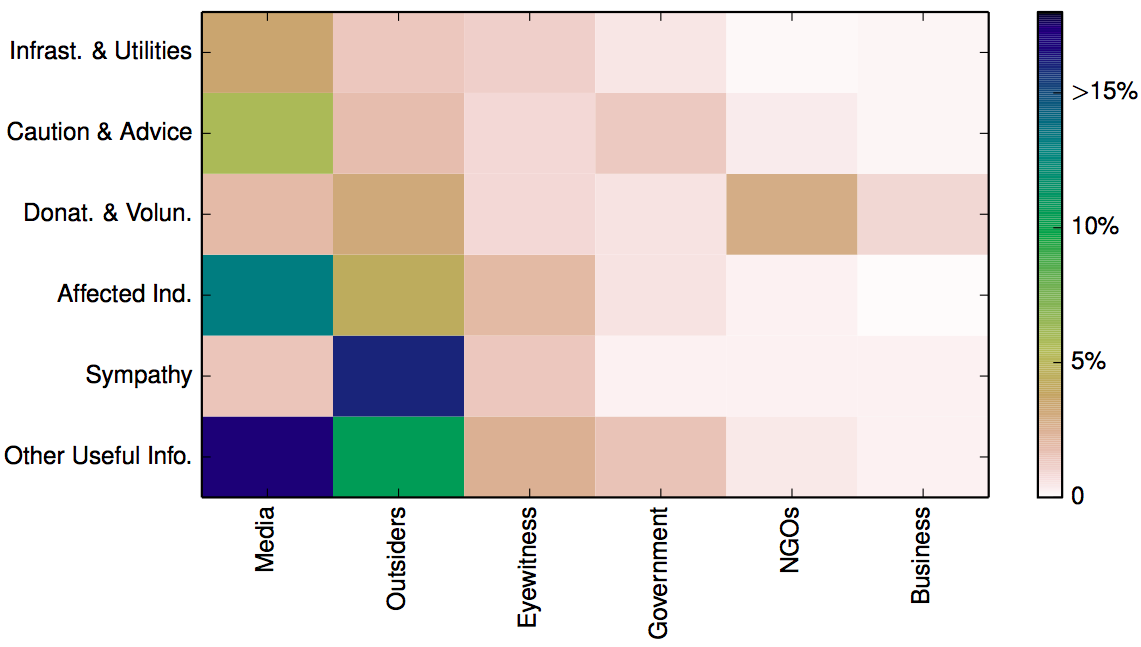
All the above findings are combined and displayed below (click to enlarge). The figure depicts the “average distribution of tweets across crises into combinations of information types (rows) and sources (columns). Rows and columns are sorted by total frequency, starting on the bottom-left corner. The cells in this figure add up to 100%.”

The above analysis suggests that “when the geographical spread [of a crisis] is diffused, the proportion of Caution and Advice tweets is above the median, and when it is focalized, the proportion of Caution and Advice tweets is below the median. For sources, […] human-induced accidental events tend to have a number of eyewitness tweets below the median, in comparison with intentional and natural hazards.” Additional analysis carried out by my colleagues indicate that “human-induced crises are more similar to each other in terms of the types of information disseminated through Twitter than to natural hazards.” In addition, crisis events that develop instantaneously also look the same when studied through the lens of tweets.
In conclusion, the analysis above demonstrates that “in some cases the most common tweet in one crisis (e.g. eyewitness accounts in the Singapore haze crisis in 2013) was absent in another (e.g. eyewitness accounts in the Savar building collapse in 2013). Furthermore, even two events of the same type in the same country (e.g. Typhoon Yolanda in 2013 and Typhoon Pablo in 2012, both in the Philippines), may look quite different vis-à-vis the information on which people tend to focus.” This suggests the uniqueness of each event.
“Yet, when we look at the Twitter data at a meta-level, our analysis reveals commonalities among the types of information people tend to be concerned with, given the particular dimensions of the situations such as hazard category (e.g. natural, human-induced, geophysical, accidental), hazard type (e.g. earth-quake, explosion), whether it is instantaneous or progressive, and whether it is focalized or diffused. For instance, caution and advice tweets from government sources are more common in progressive disasters than in instantaneous ones. The similarities do not end there. When grouping crises automatically based on similarities in the distributions of different classes of tweets, we also realize that despite the variability, human-induced crises tend to be more similar to each other than to natural hazards.”
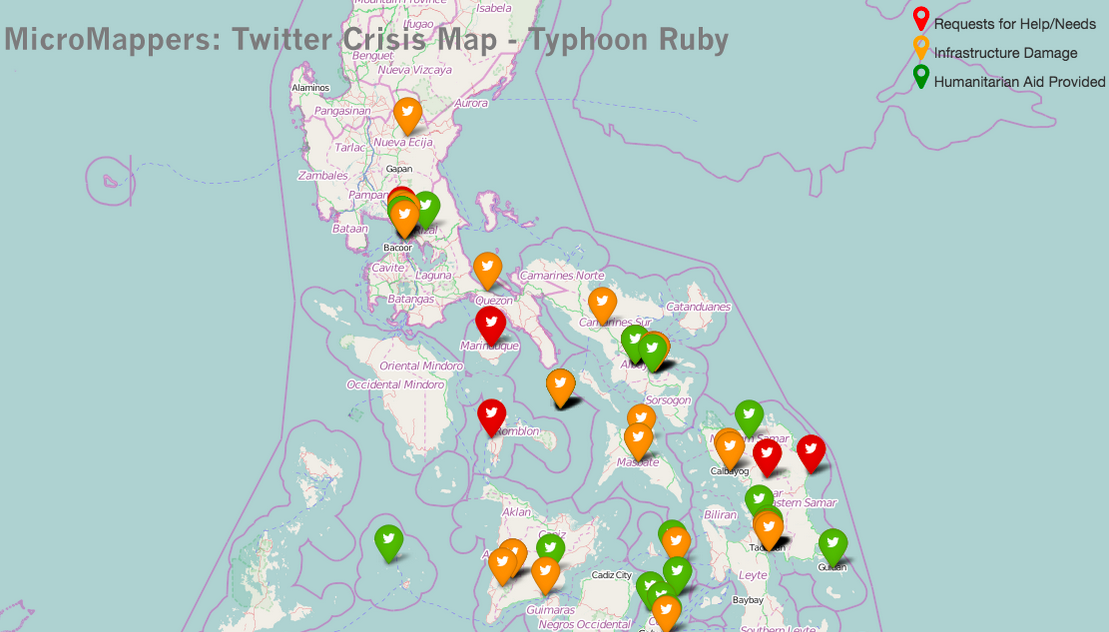
Needless to say, these are exactly the kind of findings that can improve the way we use MicroMappers & other humanitarian technologies for disaster response. So if want to learn more, the full study is available here (PDF). In addition, all the Twitter datasets used for the analysis are available at CrisisLex. If you have questions on the research, simply post them in the comments section below and I’ll ask my colleagues to reply there.

In the meantime, there is a lot more on humanitarian technology and computing in my new book Digital Humanitarians. As I note in said book, we also need enlightened policy making to tap the full potential of social media for disaster response. Technology alone can only take us so far. If we don’t actually create demand for relevant tweets in the first place, then why should social media users supply a high volume of relevant and actionable tweets to support relief efforts? This OCHA proposal on establishing specific social media standards for disaster response, and this official social media strategy developed and implemented by the Filipino government are examples of what enlightened leadership looks like.