While spam filters provide additional layers of security to websites, they can also be used to process all kinds of information. Perhaps most famously, for example, the reCAPTCHA spam filter was used to transcribe the New York Times’ entire paper-based archives. See my previous blog post to learn how this was done and how spam filters can also be used to process information for disaster response. Given the positive response I received from humanitarian colleagues who read the blog post, I teamed up with my colleagues at QCRI to create the first ever spam filter for disaster response.
During international disasters, the humanitarian community (often lead by the UN’s Office for the Coordination of Humanitarian Affairs, OCHA) needs to carry out rapid damage assessments. Recently, these assessments have included the analysis of pictures shared on social media following a disaster. For example, OCHA activated the Digital Humanitarian Network (DHN) to collect and quickly tag pictures that capture evidence of damage in response to Typhoon Pablo in the Philippines (as described here and TEDx talk above). Some of these pictures, which were found on Twitter, were also geo-referenced by DHN volunteers. This enabled OCHA to create (over night) the unique damage assessment map below.

OCHA intends to activate the DHN again in future disasters to replicate this type of rapid damage assessment operation. This is where spam filters come in. The DHN often needs support to quickly tag these pictures (which may number in the tens of thousands). Adding a spam filter that requires email users to tag which image captures disaster damage not only helps OCHA and other organizations carry out a rapid damage assessment, but also increases the security of email systems at the same time. And it only takes 3 seconds to use the spam filter.
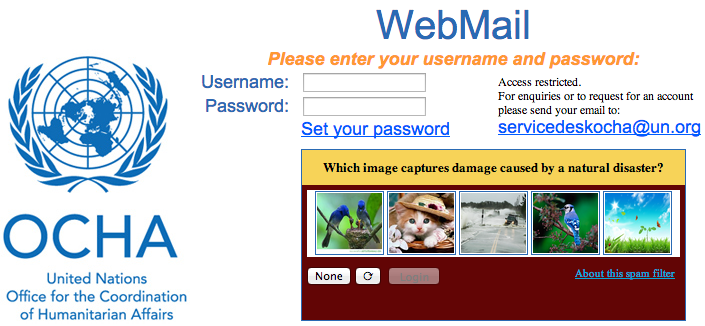
My team and I at QCRI have thus developed a spam filter plugin that can be easily added to email login pages like OCHA’s as shown above. When the Digital Humanitarian Network requires additional hands on deck to tag pictures during disasters, this plugin can simply be switched on. My team at QCRI can easily push the images to the plugin and pull data on which images have been tagged as showing disaster damage. The process for the end user couldn’t be simpler. Enter your username and password as normal and then simply select the picture below that shows disaster damage. If there are none, then simply click on “None” and then “Login”. The spam filter uses a predictive algorithm and an existing data-base of pictures as a control mechanism to ensure that the filter cannot be gamed. On that note, feel free to test the plugin here. We’d love your feedback as we continue testing.

The desired outcome? Each potential disaster picture is displayed to 3 different email account users. Only if each of the 3 users tag the same picture as capturing disaster damage does that picture get automatically forwarded to members of the Digital Humanitarian Network. To tag more pictures after logging in, users are invited to do so via MicroMappers, which launches this September in partnership with OCHA. MicroMappers enables members of the public to participate in digital disaster response efforts with a simple click of the mouse.
I would ideally like to see an innovative and forward-thinking organization like OCHA pilot the plugin for a two week feasibility test. If the results are positive and promising, then I hope OCHA and other UN agencies engaged in disaster response adopt the plugin more broadly. As mentioned in my previous blog post, the UN employs well over 40,000 people around the world. Even if “only” 10% login in one day, that’s still 4,000 images effortlessly tagged for use by OCHA and others during their disaster relief operations. Again, this plugin would only be used in response to major disasters when the most help is needed. We’ll be making the code for this plugin freely available and open source.
Please do get in touch if you’d like to invite your organization to participate in this innovative humanitarian technology project. You can support disaster response efforts around the world by simply logging into your email account, web portal, or Intranet!