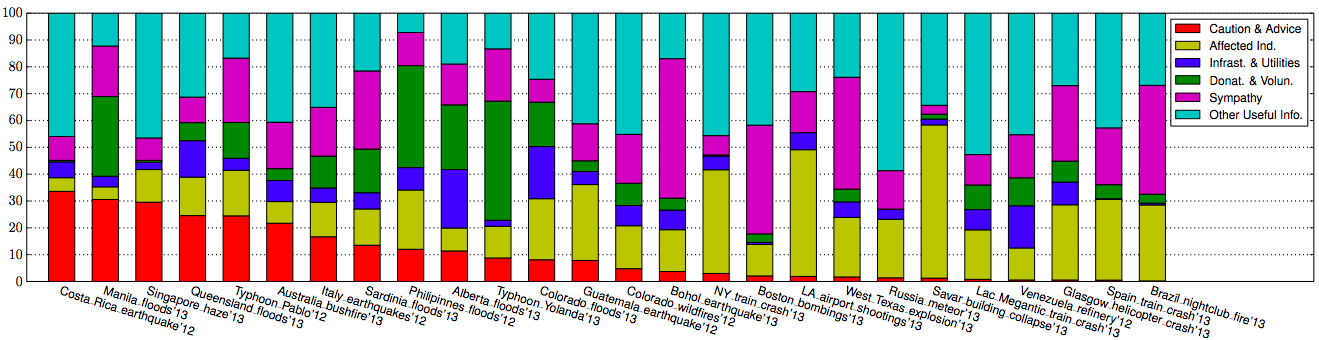
There’s no point spewing stunning statistics like this recent one from The Economist, which states that 80% of adults will have access to smartphones before 2020. The volume, velocity and variety of digital data will continue to skyrocket. To paraphrase Douglas Adams, “Big Data is big. You just won’t believe how vastly, hugely, mind-bogglingly big it is.”

And so, traditional humanitarian organizations have a choice when it comes to battling Big Data. They can either continue business as usual (and lose) or get with the program and adopt Big Data solutions like everyone else. The same goes for Digital Humanitarians. As noted in my new book of the same title, those Digital Humanitarians who cling to crowdsourcing alone as their pièce de résistance will inevitably become the ivy-laden battlefield monuments of 2020.

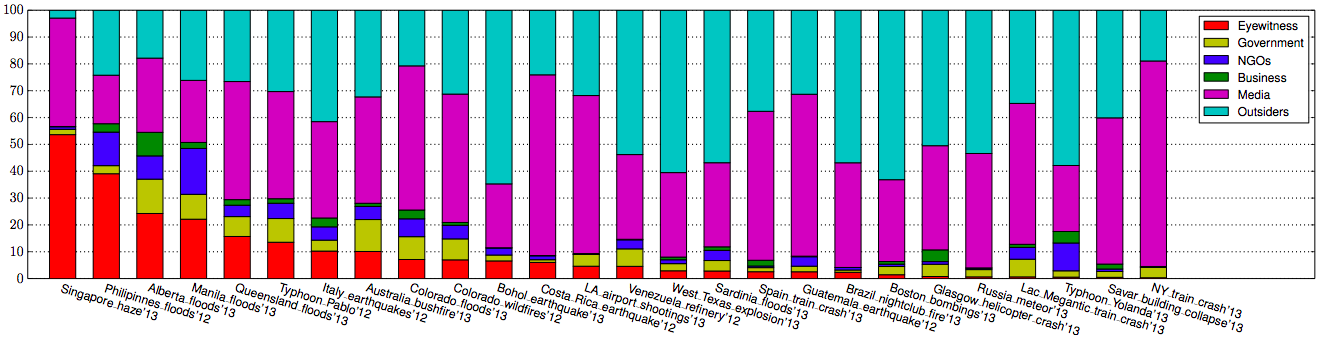
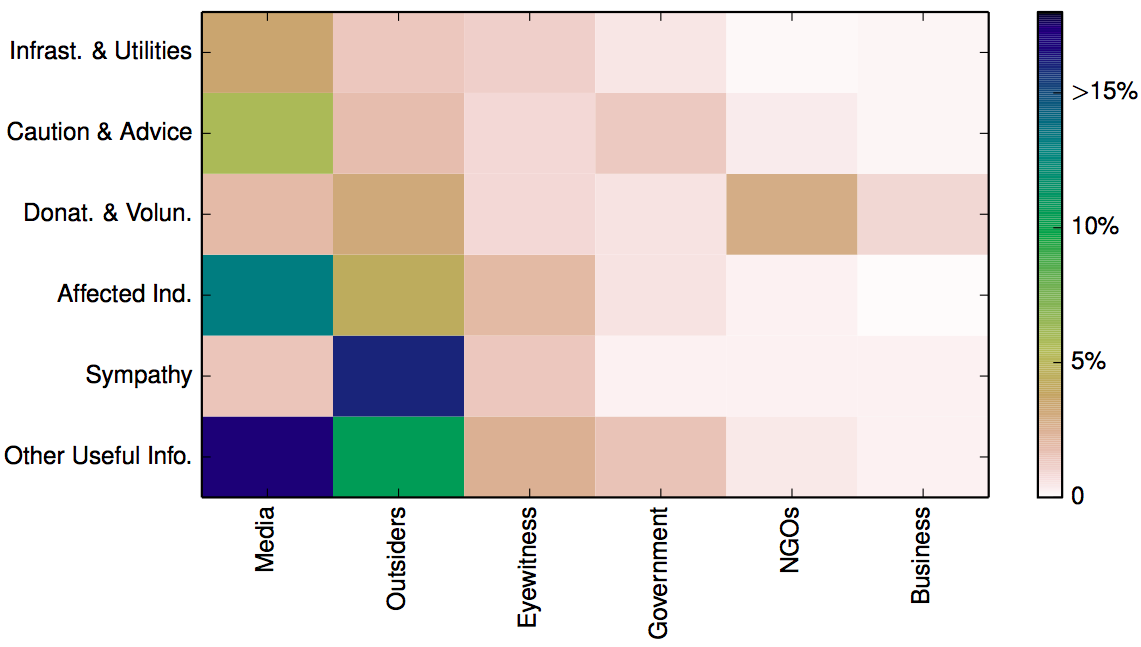
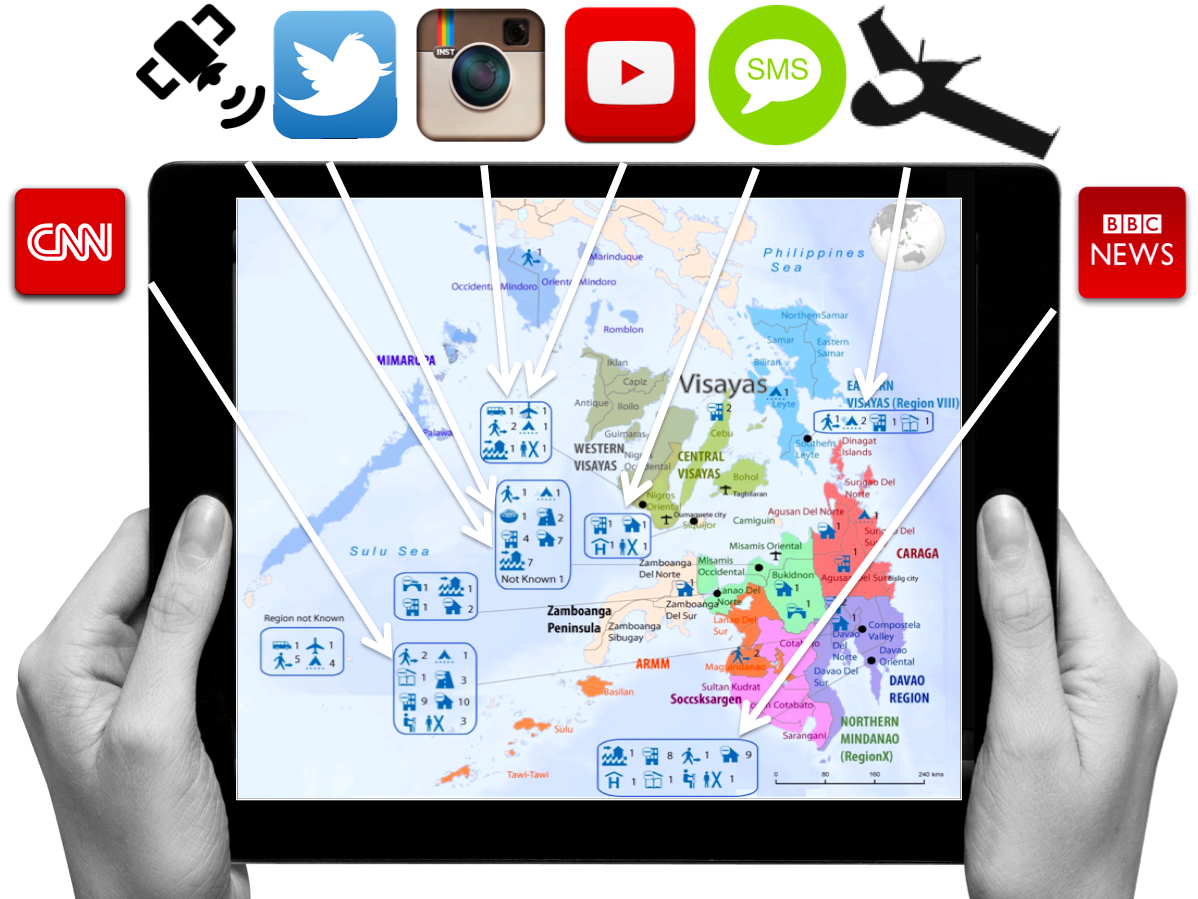
Big Data comprises a variety of data types such as text, imagery and video. Examples of text-based data includes mainstream news articles, tweets and WhatsApp messages. Imagery includes Instagram, professional photographs that accompany news articles, satellite imagery and increasingly aerial imagery as well (captured by UAVs). Television channels, Meerkat and YouTube broadcast videos. Finding relevant, credible and actionable pieces of text, imagery and video in the Big Data generated during major disasters is like looking for a needle in a meadow (haystacks are ridiculously small datasets by comparison).
Humanitarian organizations, like many others in different sectors, often find comfort in the notion that their problems are unique. Thankfully, this is rarely true. Not only is the Big Data challenge not unique to the humanitarian space, real solutions to the data deluge have already been developed by groups that humanitarian professionals at worst don’t know exist and at best rarely speak with. These groups are already using Artificial Intelligence (AI) and some form of human input to make sense of Big Data.

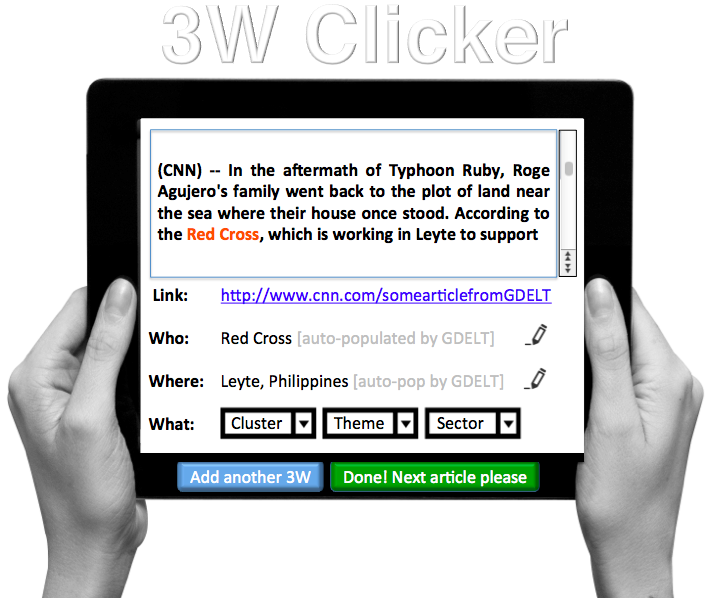
How does it work? And why do you still need some human input if AI is already in play? The human input, which can be via crowdsourcing or a few individuals is needed to train the AI engine, which uses a technique from AI called machine learning to learn from the human(s). Take AIDR, for example. This experimental solution, which stands for Artificial Intelligence for Disaster Response, uses AI powered by crowdsourcing to automatically identify relevant tweets and text messages in an exploding meadow of digital data. The crowd tags tweets and messages they find relevant and the AI engine learns to recognize the relevance patterns in real-time, allowing AIDR to automatically identify future tweets and messages.
As far as we know, AIDR is the only Big Data solution out there that combines crowdsourcing with real-time machine learning for disaster response. Why do we use crowdsourcing to train the AI engine? Because speed is of the essence in disasters. You need a crowd of Digital Humanitarians to quickly tag as many tweets/messages as possible so that AIDR can learn as fast as possible. Incidentally, once you’ve created an algorithm that accurately detects tweets relaying urgent needs after a Typhoon in the Philippines, you can use that same algorithm again when the next Typhoon hits (no crowd needed).
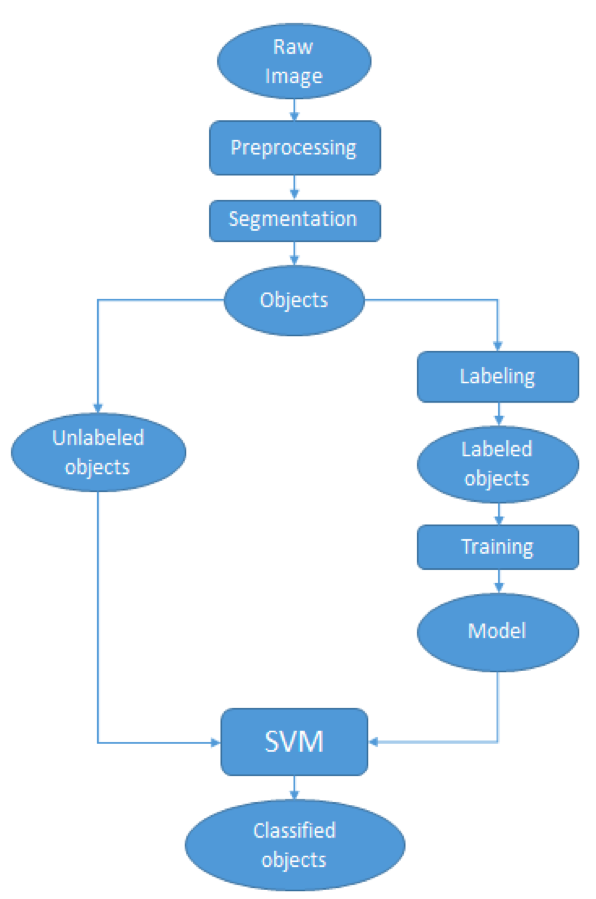
What about pictures? After all, pictures are worth a thousand words. Is it possible to combine artificial intelligence with human input to automatically identify pictures that show infrastructure damage? Thanks to recent break-throughs in computer vision, this is indeed possible. Take Metamind, for example, a new startup I just met with in Silicon Valley. Metamind is barely 6 months old but the team has already demonstrated that one can indeed automatically identify a whole host of features in pictures by using artificial intelligence and some initial human input. The key is human input since this is what trains the algorithms. The more human-generated training data you have, the better your algorithms.
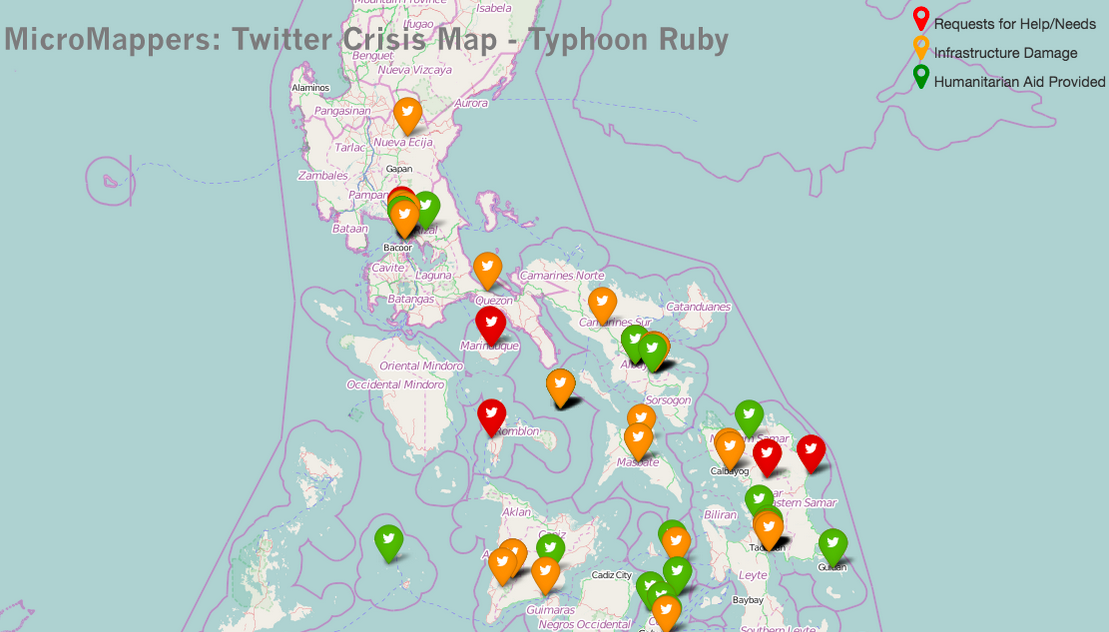
My team and I at QCRI are collaborating with Metamind to create algorithms that can automatically detect infrastructure damage in pictures. The Silicon Valley start-up is convinced that we’ll be able to create a highly accurate algorithms if we have enough training data. This is where MicroMappers comes in. We’re already using MicroMappers to create training data for tweets and text messages (which is what AIDR uses to create algorithms). In addition, we’re already using MicroMappers to tag and map pictures of disaster damage. The missing link—in order to turn this tagged data into algorithms—is Metamind. I’m excited about the prospects, so stay tuned for updates as we plan to start teaching Metamind’s AI engine this month.

How about videos as a source of Big Data during disasters? I was just in Austin for SXSW 2015 and met up with the CEO of WireWax, a British company that uses—you guessed it—artificial intelligence and human input to automatically detect countless features in videos. Their platform has already been used to automatically find guns and Justin Bieber across millions of videos. Several other groups are also working on feature detection in videos. Colleagues at Carnegie Melon University (CMU), for example, are working on developing algorithms that can detect evidence of gross human rights violations in YouTube videos coming from Syria. They’re currently applying their algorithms on videos of disaster footage, which we recently shared with them, to determine whether infrastructure damage can be automatically detected.
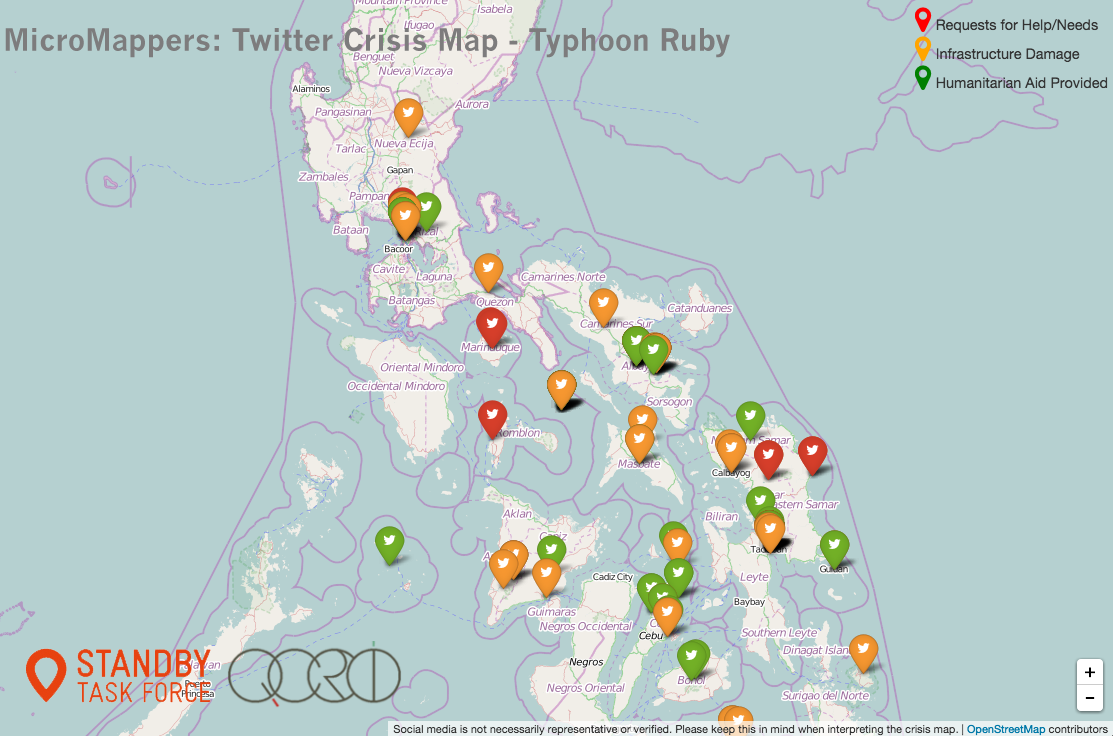
What about satellite & aerial imagery? Well the team driving DigitalGlobe’s Tomnod platform have already been using AI powered by crowdsourcing to automatically identify features of interest in satellite (and now aerial) imagery. My team and I are working on similar solutions with MicroMappers, with the hope of creating real-time machine learning solutions for both satellite and aerial imagery. Unlike Tomnod, the MicroMappers platform is free and open source (and also filters social media, photographs, videos & mainstream news).


So there you have it. The future of humanitarian information systems will not be an App Store but an “Alg Store”, i.e, an Algorithm Store providing a growing menu of algorithms that have already been trained to automatically detect certain features in texts, imagery and videos that gets generated during disasters. These algorithms will also “talk to each other” and integrate other feeds (from real-time sensors, Internet of Things) thanks to data-fusion solutions that already exist and others that are in the works.
Now, the astute reader may have noted that I omitted audio/speech in my post. I’ll be writing about this in a future post since this one is already long enough.