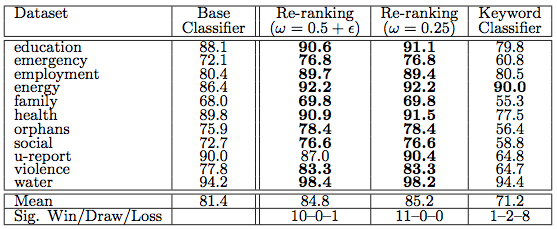
Twitter is increasingly used to communicate needs during crises. These needs often include requests for information and financial assistance, for example. Identifying these tweets in real-time requires the use of advanced computing and machine learning in particular. This is why my team and I at QCRI are developing the Artificial Intelligence for Disaster Response (AIDR) platform. My colleague Hemant Purohit has been working with us to develop machine learning classifiers to automatically identify and disaggregate between different types of needs. He has also developed classifiers to automatically identify twitter users offering different types of help including financial support. Our aim is to develop a “Match.com” solution to match specific needs with offers of help. What we’re missing, however, is for an easy way to post micro-donations on Twitter as a result of matching financial needs and offers.
![]()
This is where my colleague Clarence Wardell and his start-up TinyGive may come in. Geared towards nonprofits, TinyGive is the easiest way to accept donations on Twitter. Indeed, Donating via TinyGive is as simple as tweeting five words: “Hey @[organization], here’s $5! #tinygive”. I recently tried the service at a fundraiser and it really is that easy. TinyGive turns your tweet into an actual donation (and public endorsement), thus drastically reducing the high barriers that currently exist for Twitter users who wish to help others. Indeed, many of the barriers that currently exist in the mobile donation space is overcome by TinyGive.
Combining the AIDR platform with TinyGive would enable us to automatically identify those asking for financial assistance following a disaster and also automatically tweet a link to TinyGive to those offering financial assistance via Twitter. We’re not all affected the same way by disasters and those of us who are in proximity to said disaster but largely unscathed could use Twitter to quickly help those nearby with a simple micro-donation here and there. Think of it as time-critical, peer-to-peer localvesting.
At this recent White House event on humanitarian technology and innovation (which I had been invited to speak at but regrettably had prior commitments), US Chief Technology Office Todd Park talks about the need for “A crowdfunding platform for small businesses and others to receive access to capital to help rebuild after a disaster, including a rating system that encourages rebuilding efforts that improve the community.” Time-critical crowdfunding can build resilience and enable communities to bounce back (and forward) more quickly following a disaster. TinyGive may thus be able to play a role in building community resilience as well.
In the future, my hope is that platforms like TinyGive will also allow disaster-affected individuals (in addition to businesses and other organizations) to receive access to micro-donations during times of need directly via Twitter. There are of course important challenges still ahead, but the self-help, mutual-aid approach to disaster response that I’ve been promoting for years should also include crowdfunding solutions. So if you’ve heard of other examples like TinyGive applied to disaster response, please let me know via the comments section below. Thank you!