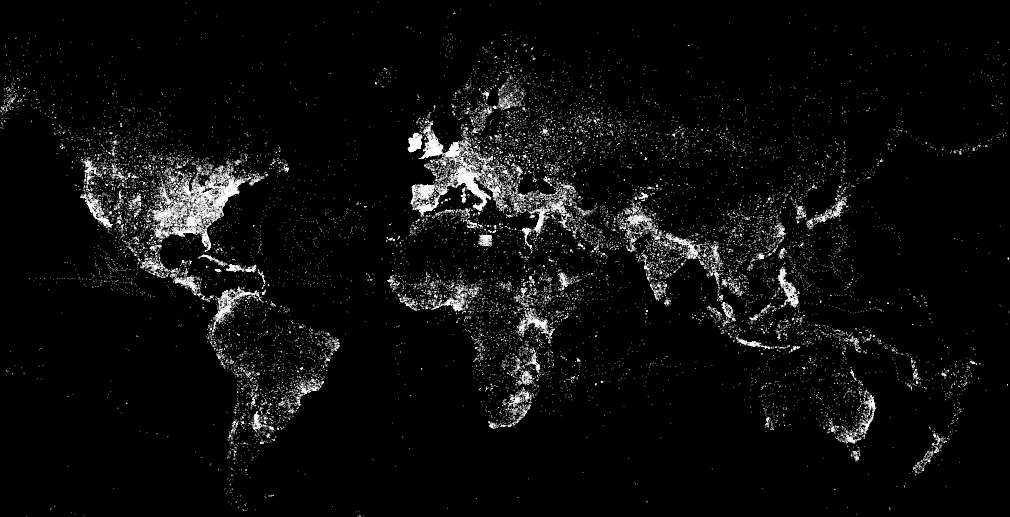
“There are hardly any street signs here. There are no official zip codes. No addresses. Just word of mouth” (1). Such is the fate of Brazil’s Mare shanty-town and that of most shantytowns around the world where the spoken word is king (and not necessarily benevolent). “The sprawling complex of slums, along with the rest of Rio de Janerio’s favelas, has hung in a sort of ‘legal invisibility’ since 1937, when a city ordinance ruled that however unsightly, favelas should be kept off maps because they were merely ‘temporary'” (2).

The socio-economic consequences were far-reaching. For decades, this infor-mality meant that “entire neighborhoods did not receive mail. It had also blocked people from giving required information on job applications, getting a bank account or telling the police or fire department where to go in an emergency call. Favela residents had to pick up their mail from their neighborhood associations, and entire slums housing a small town’s worth of residents had to use the zip code of the closest officially recognized street” (3).
All this is starting to change thanks to a grassroots initiative that is surveying Mare’s 16 favelas, home to some 130,000 people. This community-driven project has appropriated the same survey methodology used by the Brazilian government’s Institute of Geography and Statistics. The collected data includes “not only street names but the history of the original smaller favelas that make up the community” (4). This data is then “formatted into pocket guides and distributed gratis to residents. These guides also offer background on certain streets’ namesakes, but leave some blank so that residents can fill them in as Mare […] continues shifting out from the shadows of liminal space to a city with distinct identities” (5). And so, “residents of Rio’s famed favelas are undergoing their first real and ‘fundamental step toward citizenship'” (6).
These bottom-up, counter-mapping efforts are inherently political—call it guerrilla mapping. Traditionally, maps have represented “not just the per-spective of the cartographer herself, but of much larger institutions—of corporations, organizations, and governments” (7). The scale was fixed at one and only one scale, that of the State. Today, informal communities can take matters into their own hands and put themselves on the map; at the scale of their choosing. But companies like Google still have the power to make these communities vanish. In Brazil, Google said it “would tweak the site’s [Google Maps’] design, namely its text size and district labeling to show favela names only after users zoomed in on those areas.”

Meanwhile, Google is making North Korea’s capital city more visible. But I had an uncomfortable feeling after reading National Geographic’s take on Google’s citizen mapping expedition to North Korea. The Director for National Geographic Maps, Juan José Valdés, cautions that, “In many parts of the world such citizen mapping has proven challenging, if not downright dangerous. In many places, little can be achieved without the approval of local and or national authorities—especially in North Korea.” Yes, but in many parts of the world citizen mapping is safe and possible. More importantly, citizen mapping can be a powerful tool for digital activism. My entire doctoral dissertation focuses on exactly this issue.
Yes, Valdés is absolutely correct when he writes that “In many countries, place-names, let alone the alignment of boundaries, remain a powerful symbol of independence and national pride, and not merely indicators of location. This is where citizen cartographers need to understand the often subtle nuances and potential pitfalls of mapping.” As the New Yorker notes, “Maps are so closely associated with power that dictatorships regard information on geography as a state secret.” But map-savvy digital activists already know this better than most, and they deliberately seek to exploit this to their advantage in their struggles for democracy.
National Geographic’s mandate is of course very different. “From National Geographic’s perspective, all a map should accomplish is the actual portrayal of national sovereignty, as it currently exists. It should also reflect the names as closely as possible to those recognized by the political entities of the geographic areas being mapped. To do otherwise would give map readers an unrealistic picture of what is occurring on the ground.”

This makes perfect sense for National Geographic. But as James Scott reminds us in his latest book, “A great deal of the symbolic work of official power is precisely to obscure the confusion, disorder, spontaneity, error, and improvisation of political power as it is in fact exercised, beneath a billiard-ball-smooth surface of order, deliberation, rationality, and control. I think of this as the ‘miniaturization of order.'” Scott adds that, “The order, rationality, abstractness and synoptic legibility of certain kinds of schemes of naming, landscape, architecture, and work processes lend themselves to hierarchical power […] ‘landscapes of control and appropriation.'”
Citizen mapping, especially in repressive environments, often seeks to change that balance of power by redirecting the compass of political power with the use of subversive digital maps. Take last year’s example of Syrian pro-democracy activists changing place & street names depicted on on the Google Map of Syria. They did this intentionally as an act of resistance and defiance. Again, I fully understand and respect that National Geographic’s mandate is completely different to that of pro-democracy activists fighting for freedom. I just wish that Valdés had a least added one sentence to acknowledge the importance of maps for the purposes of resistance and pro-democracy movements. After all, he is himself a refugee from Cuba’s political repression.
There is of course a flip side to all this. While empowering, visibility and legibility can also undermine a community’s autonomy. As Pierre-Joseph Proudhon famously put it, “To be governed is to be watched, inspected, spied upon, directed, law-driven, numbered, regulated, enrolled, indoctrinated, preached at, controlled, checked, estimated, valued, censured, commanded, by creatures who have neither the right nor the wisdom nor the virtue to do so.” To be digitally mapped is to be governed, but perhaps at multiple scales including the preferred scale of self-governance and self-determination.
And so, we find ourselves repeating the words of Shakespeare’s famous character Hamlet: “To be, or not to be,” to map, or not to map.

See also:
- Spying with Maps [Link]
- How to Lie With Maps [Link]
- Folksomaps for Community Mapping [Link]
- From Social Mapping to Crisis Mapping [Link]
- Crisis Mapping Somalia with the Diaspora [Link]
- Perils of Crisis Mapping: Lessons from Gun Map [Link]
- Crisis Mapping the End of Sudan’s Dictatorship? [Link]
- Threat and Risk Mapping Analysis in the Sudan [Link]
- Rise of Amateur Professionals & Future of Crisis Mapping [Link]
- Google Inc + World Bank = Empowering Citizen Cartographers? [Link]
Note: Readers interested in the topics discussed above may also be interested in a forthcoming book to be published by Oxford University Press entitled “Information and Communication Technologies in Areas of Limited State-hood.” I have contributed a chapter to this book entitled “Crisis Mapping in Areas of Limited Statehood,” which analyzes how the rise of citizen-genera-ted crisis mapping replaces governance in areas of limited statehood. The chapter distills the conditions for the success of these crisis mapping efforts in these non-permissive and resource-restricted environments.