The National Academy of Engineering (NAE) and US Institute of Peace (USIP) co-organized a fascinating workshop on “Sensing & Shaping Emerging Conflicts” in November 2012. I had the pleasure of speaking at this workshop, the objective of which was to “identify major opportunities and impediments to providing better real-time information to actors directly involved in situations that could lead to deadly violence.” We explored “several scenarios of potential violence drawn from recent country cases,” and “considered a set of technologies, applications and strategies that have been particularly useful—or could be, if better adapted for conflict prevention.”

The workshop report was finally published this week. If you don’t have time to leaf through the 40+page study, then the following highlights may be of interest. One of the main themes to emerge was the promise of machine learning (ML), a branch of Artificial Intelligence (AI). These approaches “continue to develop and be applied in un-anticipated ways, […] the pressure from the peacebuilding community directed at technology developers to apply these new technologies to the cause of peace could have tremendous benefits.” On a personal note, this is one of the main reasons I joined the Qatar Computing Research Institute (QCRI); namely to apply the Institute’s expertise in ML and AI to the cause of peace, development and disaster relief.
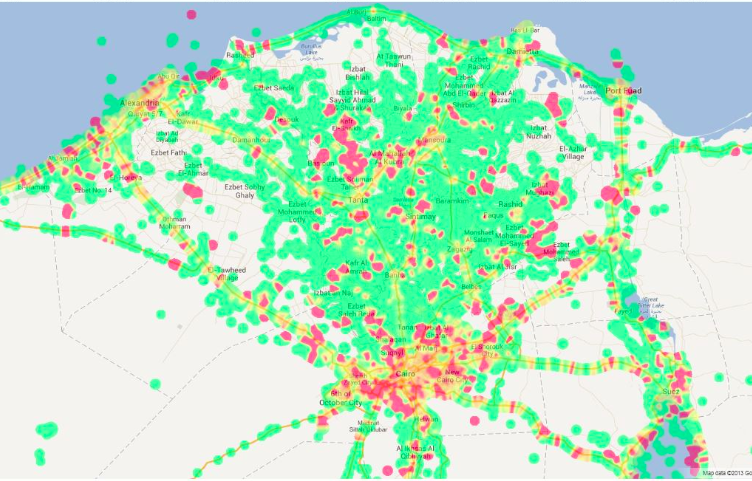
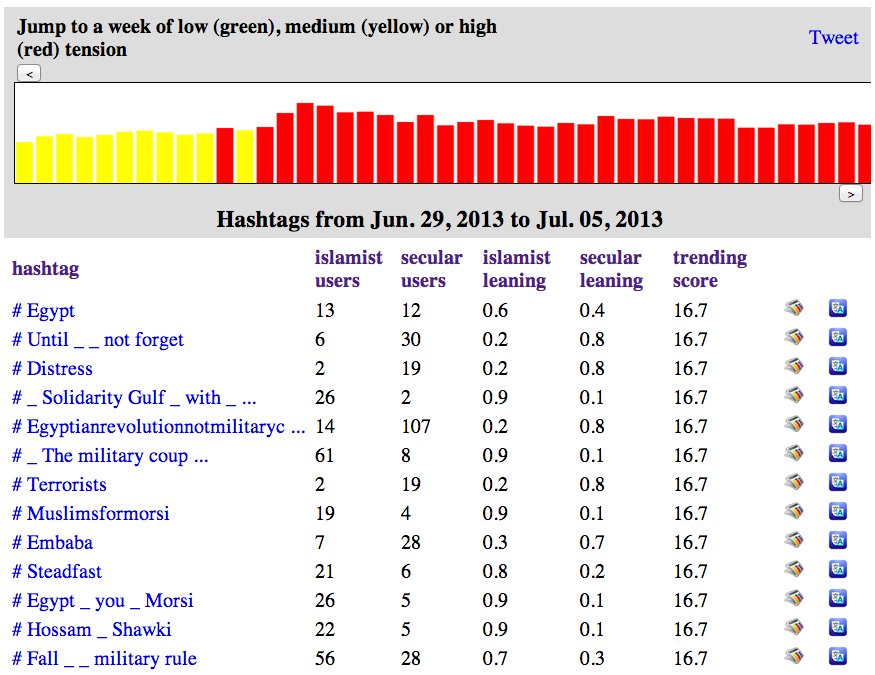
“As an example of the capabilities of new technologies, Rafal Rohozinski, principal with the SecDev Group, described a sensing exercise focused on Syria. Using social media analytics, his group has been able to identify the locations of ceasefire violations or regime deployments within 5 to 15 minutes of their occurrence. This information could then be passed to UN monitors and enable their swift response. In this way, rapid deductive cycles made possible through technology can contribute to rapid inductive cycles in which short-term predictions have meaningful results for actors on the ground. Further analyses of these events and other data also made it possible to capture patterns not seen through social media analytics. For example, any time regime forces moved to a particular area, infrastructure such as communications, electricity, or water would degrade, partly because the forces turned off utilities, a normal practice, and partly because the movement of heavy equipment through urban areas caused electricity systems go down. The electrical grid is connected to the Internet, so monitoring of Internet connections provided immediate warnings of force movements.”
This kind of analysis may not be possible in many other contexts. To be sure, the challenge of the “Digital Divide” is particularly pronounced vis-a-vis the potential use of Big Data for sensing and shaping emerging conflicts. That said, my colleague Duncan Watts “clarified that inequality in communications technology is substantially smaller than other forms of inequality, such as access to health care, clean water, transportation, or education, and may even help reduce some of these other forms of inequality. Innovation will almost always accrue first to the wealthier parts of the world, he said, but inequality is less striking in communications than in other areas.” By 2015, for example, Sub-Saharan Africa will have more people with mobile network access than with electricity at home.

My colleague Chris Spence from NDI also presented at the workshop. He noted the importance of sensing the positive and not just the negative during an election. “In elections you want to focus as much on the positive as you do on the negative and tell a story that really does convey to the public what’s actually going on and not just a … biased sample of negative reports.” Chris also highlighted that “one problem with election monitoring is that analysts still typically work with the software tools they used in the days of manual reporting rather than the Web-based tools now available. There’s an opportunity that we’ve been trying to solve, and we welcome help.” Building on our expertise in Machine Learning and Artificial Intelligence, my QCRI colleagues and I want to develop classifiers that automatically categorize large volumes of crowdsourced election reports. So I’m exploring this further with Chris & NDI. Check out the Artificial Intelligence for Monitoring Elections (AIME) project for more information.
One of the most refreshing aspects of the day-long workshop was the very clear distinction made between warning and response. As colleague Sanjana Hattotuwa cautioned: “It’s an open question whether some things are better left unsaid and buried literally and metaphorically.” Duncan added that, “The most important question is what to do with information once it has been gathered.” Indeed, “Simply giving people more information doesn’t necessarily lead to a better outcome, although some-times it does.” My colleague Dennis King summed it up very nicely, “Political will is not an icon on your computer screen… Generating political will is the missing factor in peacebuilding and conflict resolution.”
In other words, “the peacebuilding community often lacks actionable strategies to convert sensing into shaping,” as colleague Fred Tipson rightly noted. Libbie Prescott, who served as strategic advisor to the US Secretary of State and participated in the workshop, added: “Policymakers have preexisting agendas, and just presenting them with data does not guarantee a response.” As my colleague Peter Walker wrote in a book chapter published way back in 1992, “There is little point in investing in warning systems if one then ignores the warnings!” To be clear, “early warning should not be an end in itself; it is only a tool for preparedness, prevention and mitigation with regard to disasters, emergencies and conflict situations, whether short or long term ones. […] The real issue is not detecting the developing situation, but reacting to it.”
Now Fast froward to 2013: OCHA just published this groundbreaking report confirming that “early warning signals for the Horn of Africa famine in 2011 did not produce sufficient action in time, leading to thousands of avoidable deaths. Similarly, related research has shown that the 2010 Pakistan floods were predictable.” As DfID notes in this 2012 strategy document, “Even when good data is available, it is not always used to inform decisions. There are a number of reasons for this, including data not being available in the right format, not widely dispersed, not easily accessible by users, not being transmitted through training and poor information management. Also, data may arrive too late to be able to influence decision-making in real time operations or may not be valued by actors who are more focused on immediate action” (DfID). So how do we reconcile all this with Fred’s critical point: “The focus needs to be on how to assist the people involved to avoid the worst consequences of potential deadly violence.”

The fact of the matter is that this warning-response gap in the field of conflict prevention is over 20 years old. I have written extensively about the warning-response problem here (PDF) and here (PDF), for example. So this challenge is hardly a new one, which explains why a number of innovative and promising solutions have been put forward of the years, e..g, the decentralization of conflict early warning and response. As my colleague David Nyheim wrote five years ago:
“A state-centric focus in conflict management does not reflect an understanding of the role played by civil society organisations in situations where the state has failed. An external, interventionist, and state-centric approach in early warning fuels disjointed and top down responses in situations that require integrated and multilevel action.” He added: “Micro-level responses to violent conflict by ‘third generation early warning systems’ are an exciting development in the field that should be encouraged further. These kinds of responses save lives.”
This explains why Sanjana is right when he emphasizes that “Technology needs to be democratized […], made available at the lowest possible grassroots level and not used just by elites. Both sensing and shaping need to include all people, not just those who are inherently in a position to use technology.” Furthermore, Fred is spot on when he says that “Technology can serve civil disobedience and civil mobilization […] as a component of broader strategies for political change. It can help people organize and mobilize around particular goals. It can spread a vision of society that contests the visions of authoritarian.”
In sum, As Barnett Rubin wrote in his excellent book (2002) Blood on the Doorstep: The Politics of Preventive Action, “prevent[ing] violent conflict requires not merely identifying causes and testing policy instruments but building a political movement.” Hence this 2008 paper (PDF) in which I explain in detail how to promote and facilitate technology-enabled civil resistance as a form of conflict early response and violence prevention.

See Also:
- Big Data for Conflict Prevention [Link]


















{kind=link}