Over 1 million unique users posted more than 2.7 million tweets in just 3 days following the triple bomb blasts that struck Mumbai on July 13, 2011. Out of these, over 68,000 tweets were “original tweets” (in contrast to retweets) and related to the bombings. An analysis of these tweets yielded some interesting patterns. (Note that the Ushahidi Map of the bombings captured ~150 reports; more here).

One unique aspect of this study (PDF) is the methodology used to assess the quality of the Twitter dataset. The number of tweets per user was graphed in order to test for a power law distribution. The graph below shows the log distri-bution of the number of tweets per user. The straight lines suggests power law behavior. This finding is in line with previous research done on Twitter. So the authors conclude that the quality of the dataset is comparable to the quality of Twitter datasets used in other peer-reviewed studies.

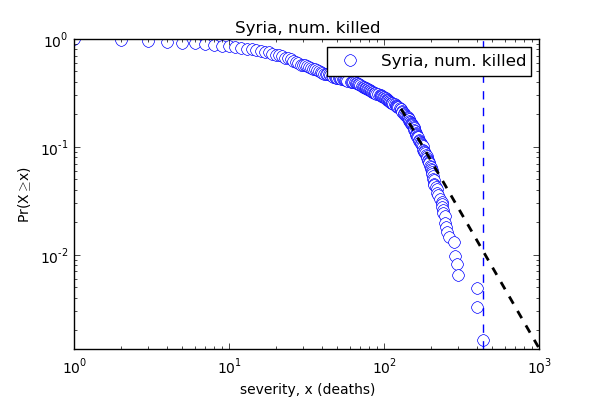
I find this approach intriguing because Professor Michael Spagat, Dr. Ryan Woodard and I carried out related research on conflict data back in 2006. One fascinating research question that emerges from all this, and which could be applied to twitter datasets, is whether the slope of the power law says anything about the type of conflict/disaster being tweeted about, the expected number of casualties or even the propagation of rumors. If you’re interested in pursuing this research question (and have worked with power laws before), please do get in touch. In the meantime, I challenge the authors’ suggestion that a power law distribution necessarily says anything about the quality or reliability of the underlying data. Using the casualty data from SyriaTracker (which is also used by USAID in their official crisis maps), my colleague Dr. Ryan Woodard showed that this dataset does not follow a power law distribution—even thought it is one of the most reliable on Syria.
Moving on to the content analysis of the Mumbai blast tweets: “The number of URLs and @-mentions in tweets increase during the time of the crisis in com-parison to what researchers have exhibited for normal circumstances.” The table below lists the top 10 URLs shared on Twitter. Inter-estingly, the link to a Google Spreadsheet was amongst the most shared resource. Created by Twitter user Nitin Sagar, the spreadsheet was used to “coordinate relief operation among people. Within hours hundreds of people registered on the sheet via Twitter. People asked for or off ered help on that spreadsheet for many hours.”

The analysis also reveals that “the number of tweets or updates by authority users (those with large number of followers) are very less, i.e., majority of content generated on Twitter during the crisis comes from non authority users.” In addition, tweets generated by authority users have a high level of retweets. The results also indicate that “the number of tweets generated by people with large follower base (who are generally like government owned accounts, cele-brities, media companies) were very few. Thus, the majority of content generated at the time of crisis was from unknown users. It was also observed that, though the number of posts were less by users with large number of followers, these posts registered high numbers of retweets.”
Rumors related to the blasts also spread through Twitter. For example, rumors began to circulate about a fourth bomb going off. “Some tweets even speci fied locations of 4th blast as Lemington street, Colaba and Charni. Around 500+ tweets and retweets were posted about this.” False rumors about hospital blood banks needing donations were also propagated via Twitter. “They were initiated by a user, @KapoorChetan and around 2,000 tweets and retweets were made regarding this by Twitter users.” The authors of the study believe that such false rumors and can be prevented if credible sources like the mainstream media companies and the government post updates on social media more frequently.
I did a bit of research on this and found that NDTV did use their twitter feed (which has over half-a-million followers) to counter these rumors. For example, “RT @ndtv: Mumbai police: Don’t believe rumours of more bombs. False rumours being spread deliberately.” Journalist Sonal Kalra also acted to counter rumors: “RT @sonalkalra: BBMs about bombs found in Delhi are FALSE. Pls pls don’t spread rumours. #mumbaiblasts.”

In conclusion, the study considers the “privacy threats during the Twitter activity after the blasts. People openly tweeted their phone numbers on social media websites like Twitter, since at such moment of crisis people wished to reach out to help others. But, long after the crisis was over, such posts still remained publicly available on the Internet.” In addition, “people also openly posted their blood group, home address, etc. on Twitter to off er help to victims of the blasts.” The Ushahidi Map also includes personal information. These data privacy and security issues continue to pose major challenges vis-a-vis the use of social media for crisis response.

See also: Did Terrorists Use Twitter to Increase Situational Awareness? [Link]