Update: Please help the UN! Tag tweets to support disaster response!
The purpose of this post is to keep notes on our efforts to date with the aim of revisiting these at a later time to write a more polished blog post on said efforts. By “Digital Humanitarian Response” I mean the process of using digital tech-nologies to aid disaster response efforts.

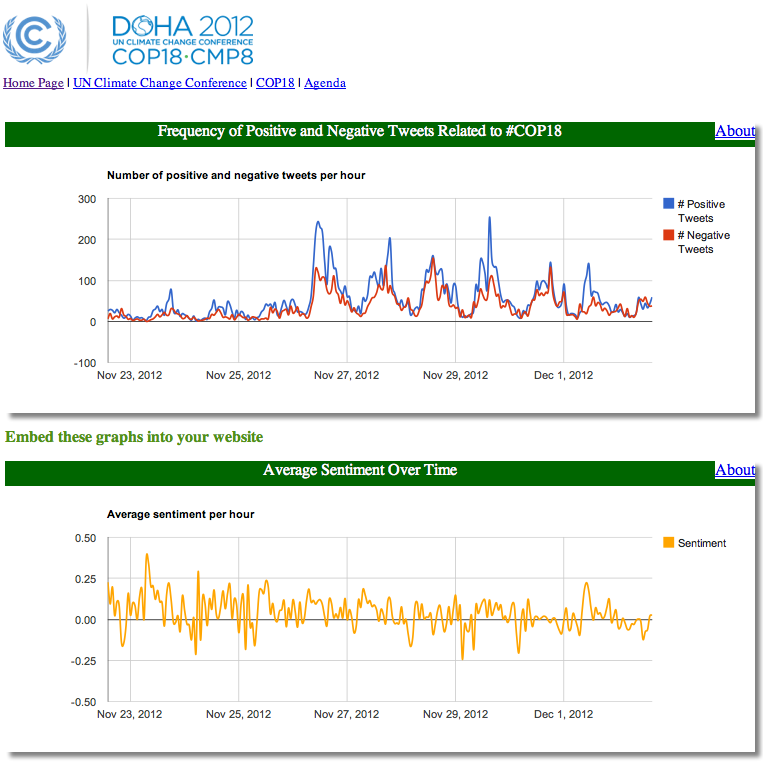
My colleagues and I at QCRI have been collecting disaster related tweets on Typhoon Pablo since Monday. More specifically, we’ve been collecting those tweets with the hashtags officially endorsed by the government. There were over 13,000 relevant tweets posted on Tuesday alone. We then paid Crowdflower workers to micro-task the tagging of these hash-tagged tweets based on the following categories (click picture to zoom in):
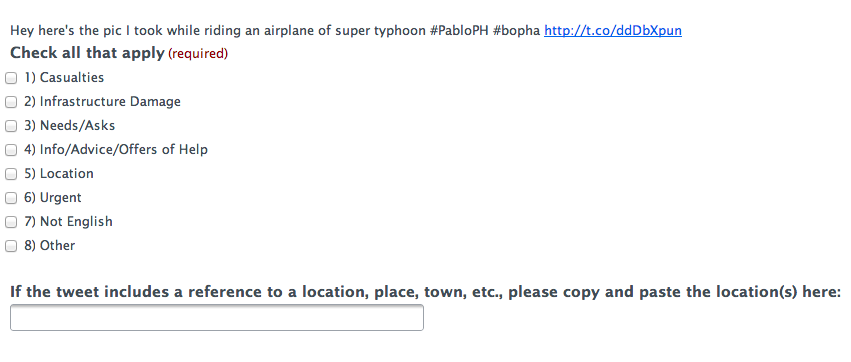
Several hundred tweets were processed during the first hour. On average, about 750 tweets were processed per hour. Clearly, we’d want that number to be far higher, (hence the need to combine micro-tasking with automated algorithms, as explained in the presentation below). In any event, the micro-tasking could also be accelerated if we increased the pay to Crowdflower workers. As it is, the total cost for processing the 13,000+ tweets came to about $250.
The database of processed tweets was then shared (every couple hours) with the Standby Volunteer Task Force (SBTF). SBTF volunteers (“Mapsters”) only focused on tweets that had been geo-tagged and tagged as relevant (e.g., “Casaualties,” “Infrastructure Damage,” “Needs/Asks,” etc.) by Crowdflower workers. SBTF volunteers then mapped these tweets on a Crowdmap as part of a training exercise for new Mapsters.
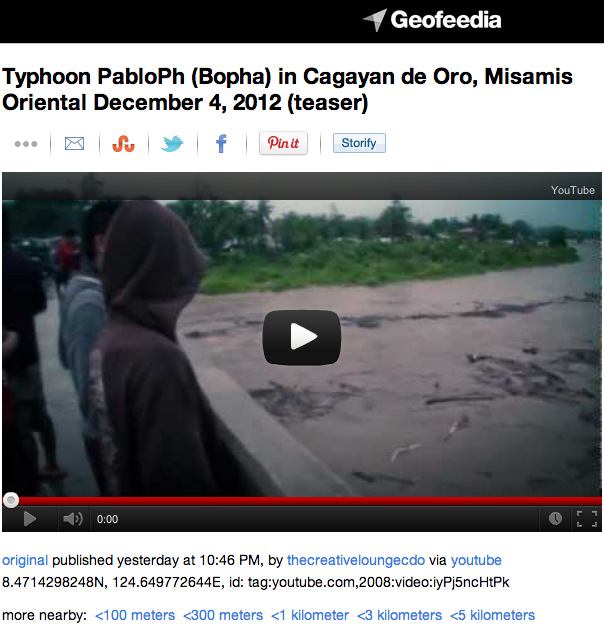
We’re now talking with a humanitarian colleague in the Philippines who asked whether we can identify pictures/videos shared on social media that show damage, bridges down, flooding, etc. The catch is that these need to have a location and time/date for them to be actionable. So I went on Geofeedia and scraped the relevant content available there (which Mapsters then added to the Crowdmap). One constraint of Geofeedia (and many other such platforms), however, is that they only map content that has been geo-tagged by users posting said content. This means we may be missing the majority of relevant content.
So my colleagues at QCRI are currently pulling all tweets posted today (Wed-nesday) and running an automated algorithm to identify tweets with URLs/links. We’ll ask Crowdflower workers to process the most recent tweets (and work backwards) by tagging those that: (1) link to pictures/video of damage/flooding, and (2) have geographic information. The plan is to have Mapsters add those tweets to the Crowdmap and to share the latter with our humanitarian colleague in the Philippines.
There are several parts of the above workflows that can (and will) be improved. I for one have already learned a lot just from the past 24 hours. But this is the subject of a future blog post as I need to get back to the work at hand.